We live in a world where huge volumes of data are generated every single day, from our smartphones to what we search on Google or Bing; what we post, like, comment, or share on different social media platforms; what we buy on e-commerce sites; data generated by machines and other sources. We are in the Data Age and data is the new oil.

Quick fact: This article in Forbes states that "The amount of data that we produce every day is truly mind-boggling. There are 2.5 quintillion bytes of data created each day at our current pace."
Data has a lot of potential if you can find insights from it, and it allows you to make data-driven decisions your area of business instead of depending on your experiences. Big to small companies have started to use data to understand their customers better, improve sales and marketing behaviors, and make accurate decisions for their business.
The question is, how you can start finding insights from your data in order to make data-driven decisions?
It all starts by exploring your data to find and understand the hidden patterns, knowledge, and facts that can help you to make a better decision.
In this article, you will learn:
- Exploratory data analysis
- Importances of exploratory data analysis
- Python packages you can use to explore your data
- Practical example with a real-world dataset
What is Exploratory Data Analysis?
Exploratory Data Analysis (EDA) refers to the critical process of performing initial investigations on data to discover patterns, to spot anomalies, to test hypotheses and to check assumptions with the help of summary statistics and graphical representations. It is good practice to understand the data first and try to gather initial insights from it.
Why is Exploratory Data Analysis important?
By exploring your data you can benefit in different ways like:
- Identifyingthe most important variables/features in your dataset
- Testing a hypothesis or checking assumptions related to the dataset
- To check the quality of the data for further processing and cleaning
- Deliver data-driven insights to business stakeholders
- Verify that expected relationships actually exist in the data
- To find unexpected structures or patterns in the data
Python packages for Exploratory Data Analysis
The following python packages will help you to start exploring your dataset:
- Pandas is a python package focus on data analysis
- NumPy is a general purpose array-processing package
- Matplotlib is a Python 2D plotting library which produces publication quality figures in a varietyy of formats
- Seaborn is a Python dat visualization library based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics
Now you know what EDA is and its benefits, let move on to explore the Financial Inclusion in Africa dataset from Zindi so that you can understand important steps to follow when you analyze your own dataset.
Exploratory Data Analysis for Financial Inclusion in Africa dataset
The first important step is to understand the problem statement about the dataset you are going to analyze. This will help you to generate hypotheses or assumptions about the dataset.
1. Understand the problem statement
Financial inclusion remains one of the main obstacles to economic and human development in Africa. For example, across Kenya, Rwanda, Tanzania, and Uganda, only 9.1 million adults (or 13.9% of the adult population) have access to or use commercial bank accounts.
Traditionally, access to a bank account has been regarded as an indicator of financial inclusion. Despite the proliferation of mobile money in Africa and the growth of innovative FinTech solutions, banks still play a pivotal role in facilitating access to financial services. Access to bank accounts enable households to save and make payments while also helping businesses build up their credit-worthiness and improve their access to other financial services. Therefore, access to a bank account is an essential contibutor to long-term economic growth.
To know more about the problem statement visit the competition page.
2. Type of the problem
After going through the problem statement, the dataset focuses on a classification where you have to predict whether individuals are most likely to have or use a bank account or not. But you will not apply a machine learning technique in this article.
3. Generating a hypothesis
This is a very important stage during data exploration. It involves understanding the problem in detail by brainstorming as many factors as possible which can impact the outcome. It is done by understanding the problem statement thoroughly and before looking at the data.
Below are some of the factors which I think can affect the chance for a person to have a bank account:
- People who have mobile phones have a lower chance to use bank accounts because of mobile money services
- People who are employed have a higher chance of having bank accounts than people who are employed
- People in rural areas have a low chance to have bank accounts
- Females have less chance to have bank accounts
Now let's load and analyze our dataset to see if assumptions generated are valid or not valid. You can download the dataset and notebook here.
4. Load Python packages and dataset
We import all important Python packages to start analyzing our dataset.
# import important modules
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns plt.rcParams["axes.labelsize"] = 18
import warnings
warnings.filterwarnings('ignore') %matplotlib inlineLoad Financial Inclusion dataset:
# Import data
data = pd.read_csv('../data/financial_inclusion.csv')Let's see the shape of our data:
# print shape
print('train data shape :', data.shape)
train data shape : (23524, 13)
In our dataset, we have 13 columns and 23544 rows.
We can observe the first five rows from our data set by using the head() method from the pandas library.
# Inspect Data by showing the first five rows data.head()
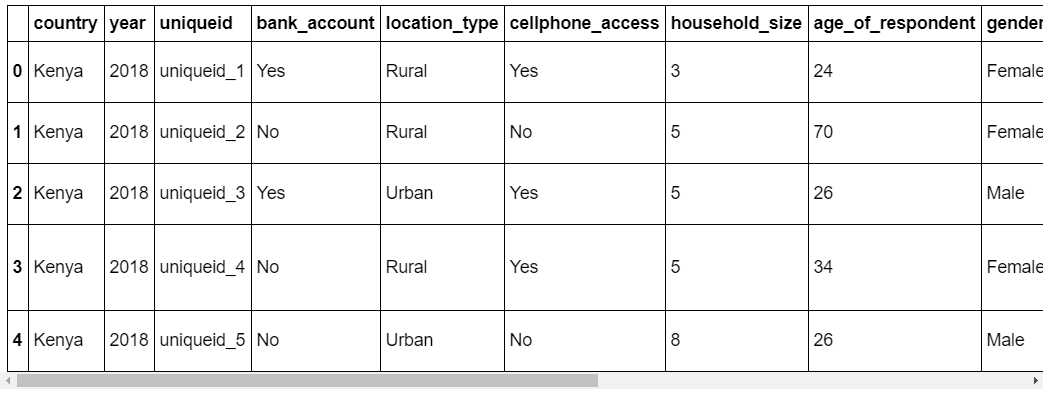
It is important to understand the meaning of each feature so you can really understand the dataset. Click here to get the defintion of each feature presented in the dataset
We can get more information about the features presented by using the info() method from pandas.
## show Some information about the dataset print(data.info())
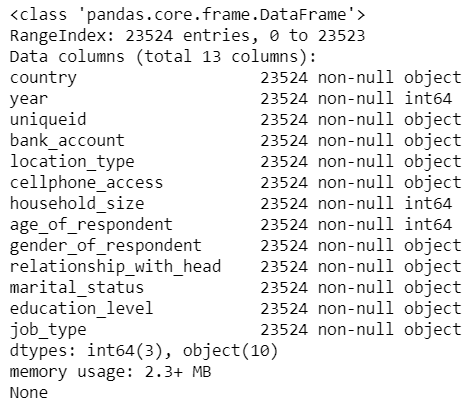
The output shows the list of variables/features and sizes, and if it contains missing values and data type for each variable. From the dataset, we don't have any missing values and we have 3 features of integer data type and 10 features of the object data type.
If you want to learn how to handle missing data in your dataset, I recommend you read How to handle missing data with Python by Jason Brownlee.
5. Univariate Analysis
In this section, we will do the univariate analysis. It is the simplest form of analyzing data where we examine each variable individually. For categorical features, we can use frequency tables or bar plots which will calculate the number of each category in a particular variable. For numerical features, probability density plots can be used to look at the distribution of the variable.
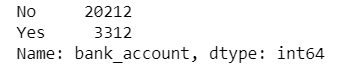
The following codes show unique values in the bank_account variable where Yes means the person has a bank account and No means the person doesn't have a bank account.
# Frequency table of a variable will give us the count of each category in that Target variable. data['bank_account'].value_counts()
# Explore Target distribution sns.catplot(x="bank_account", kind="count", data= data)
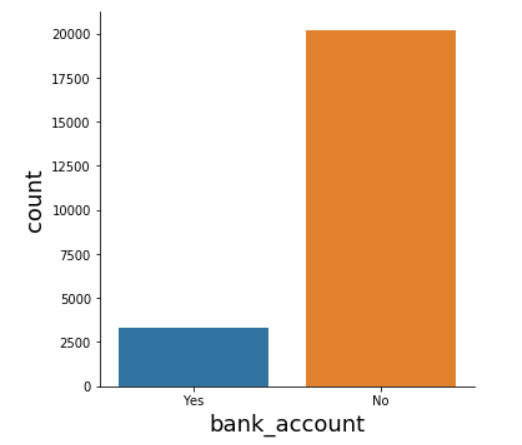
The data shows that we have a larger number of no class than yes class in our target variable, which means a majority of people don't have bank accounts.
# Explore Country distribution sns.catplot(x="country", kind="count", data=data)
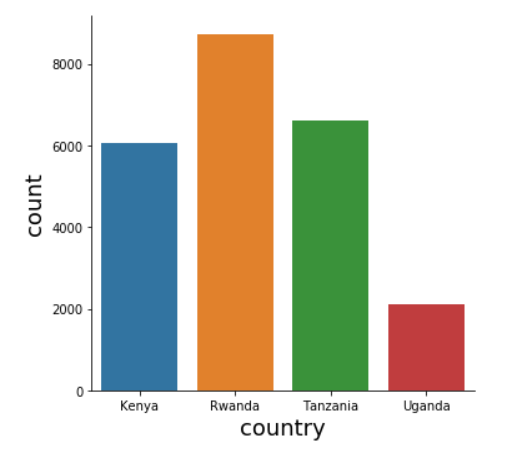
The country feature in the above graph shows that most of the data was collected in Rwanda and the least data was collected in Uganda.
# Explore Location distribution sns.catplot(x="location_type", kind="count", data=data)
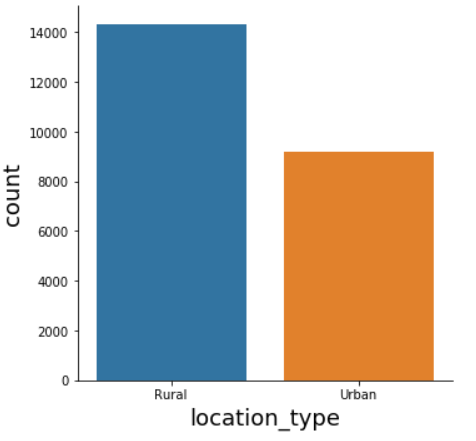
In the location_type feature, we have a larger number of people living in rural areas than in urban areas.
# Explore Years distribution sns.catplot(x="year", kind="count", data=data)
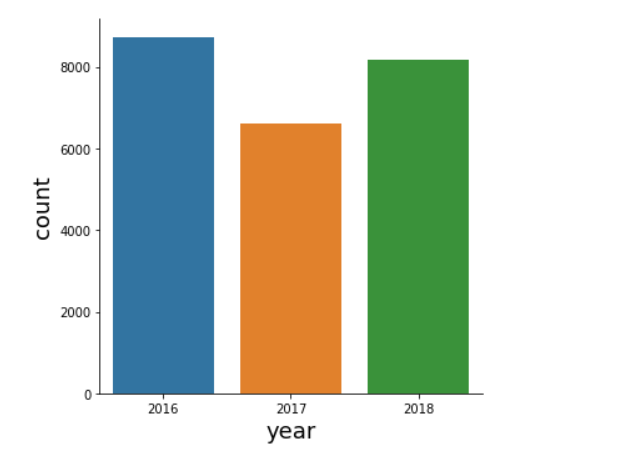
In the year feature, most of the data was collected in 2016.
# Explore cellphone_access distribution sns.catplot(x="cellphone_access", kind="count", data=data)
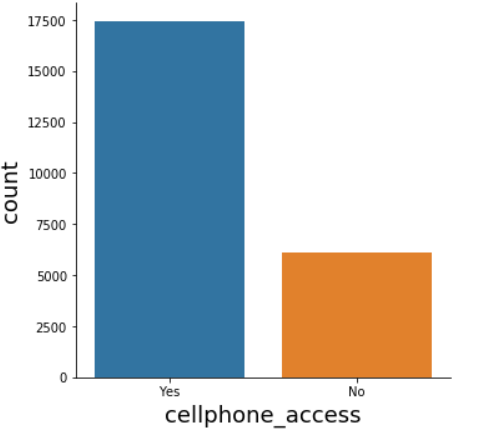
In the cellphone_access feature, most of the participants have access to a cellphone.
# Explore gender_of_respondents distribution sns.catplot(x="gender_of_respondent", kind="count", data=data)
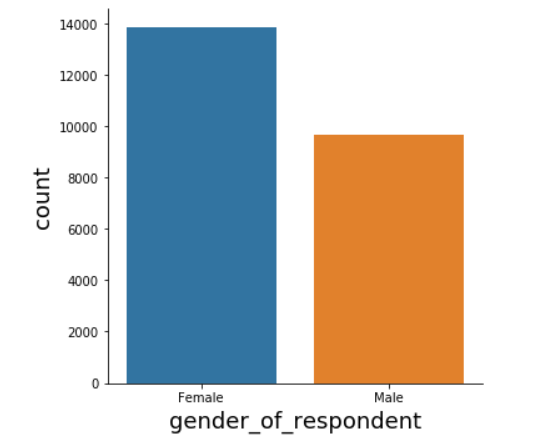
In the gender_of_respondent feature, we have more females than males.
# Explore relationship_with_head distribution
sns.catplot(x="relationship_with_head", kind="count", data=data);
plt.xticks(
rotation=45,
horizontalalignment='right',
fontweight='light',
fontsize='x-large'
)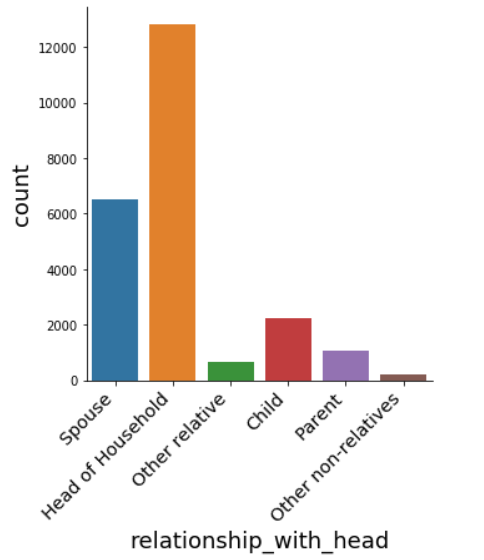
In the relationship_with_head feature, we have more heads of household participants and few other non-relatives.
# Explore marital_status distribution
sns.catplot(x="marital_status", kind="count", data=data);
plt.xticks(
rotation=45,
horizontalalignment='right',
fontweight='light',
fontsize='x-large'
)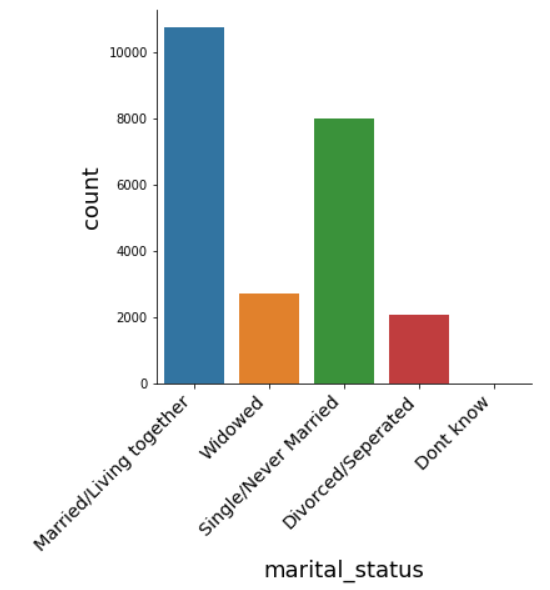
In the marital_status feature, most of the participants are married/living together.
# Explore education_level distribution
sns.catplot(x="education_level", kind="count", data=data);
plt.xticks(
rotation=45,
horizontalalignment='right',
fontweight='light',
fontsize='x-large'
)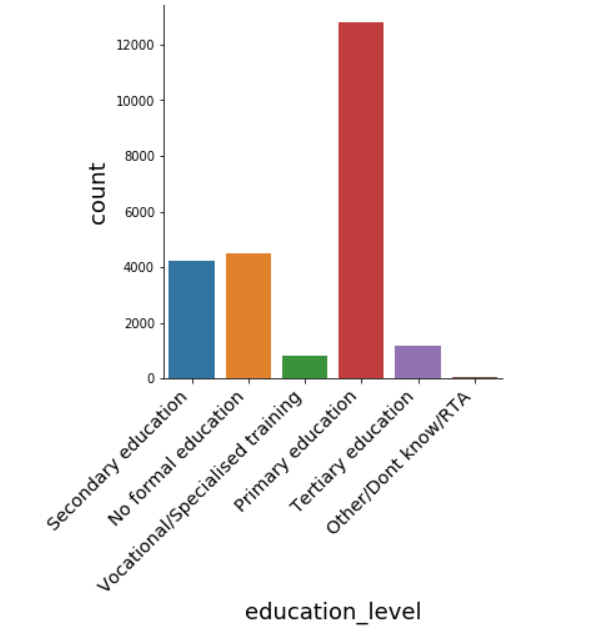
In the education_level feature, most of the participants have a primary level of education.
# Explore job_type distribution sns.catplot(x="job_type", kind="count", data=data); plt.xticks( rotation=45, horizontalalignment='right', fontweight='light', fontsize='x-large' )
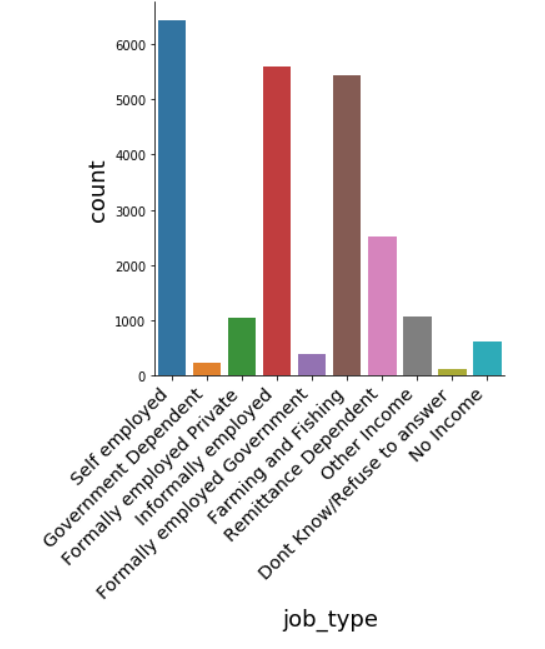
In the job_type feature, most of the participants are self-employed.
# Explore household_size distribution
plt.figure(figsize=(16, 6))
data.household_size.hist()
plt.xlabel('Household size')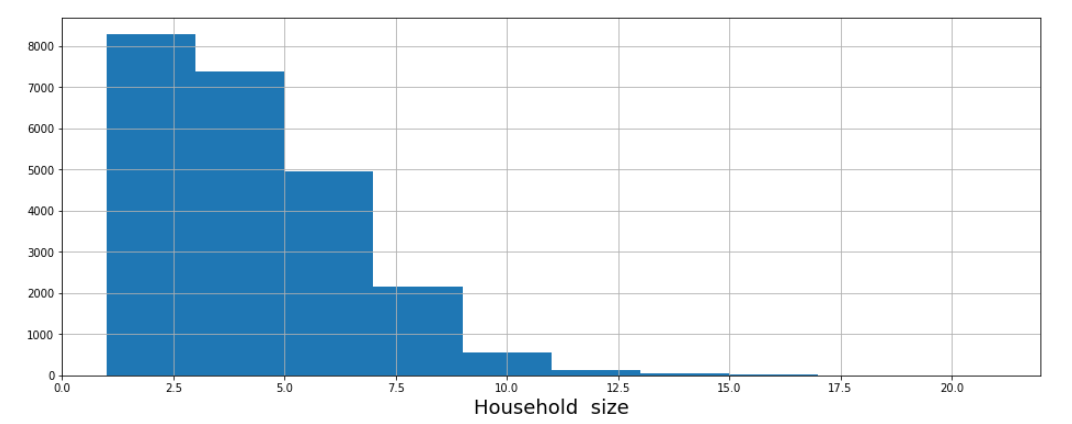
Household_size is not normally distributed and the most common number of people living in the house is 2.
# Explore age_of_respondent distribution
plt.figure(figsize=(16, 6))
data.age_of_respondent.hist()
plt.xlabel('Age of Respondent')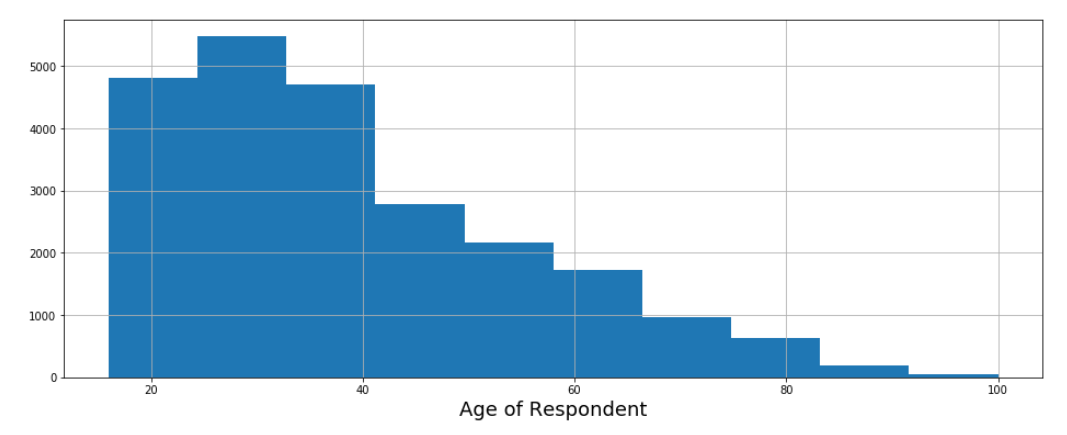
In our last feature called age_of_respondent, most of the participants are between 25 and 35 years old.
6. Bivariate Analysis
Bivariate analysis is the simultaneous analysis of two variables (attributes). It explores the concept of the relationship between two variables, whether an association exists and the strength of this association, or whether there are differences between two variables and the significance of these differences.
After looking at every variable individually in Univariate analysis, we will now explore them again with respect to the target variable.
#Explore location type vs bank account
plt.figure(figsize=(16, 6))
sns.countplot('location_type', hue= 'bank_account', data=data)
plt.xticks(
fontweight='light',
fontsize='x-large'
)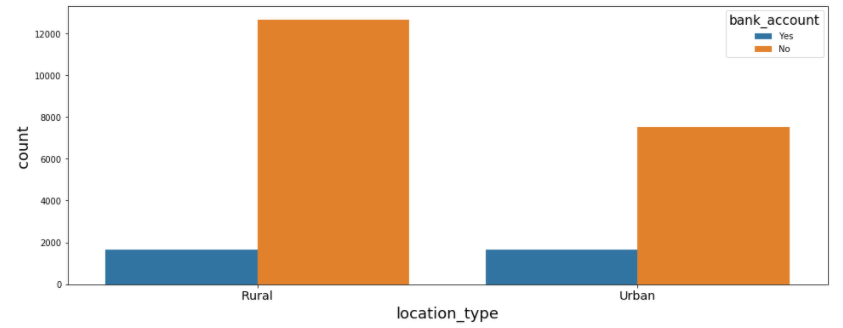
From the above plot, you can see that the majority of people living in rural areas don't have bank accounts. Therefore our assumption we made during the hypothesis generation is valid that people live in rural areas have a low chance to have bank accounts.
#Explore gender_of_respondent vs bank account
plt.figure(figsize=(16, 6))
sns.countplot('gender_of_respondent', hue= 'bank_account', data=data)
plt.xticks(
fontweight='light',
fontsize='x-large'
)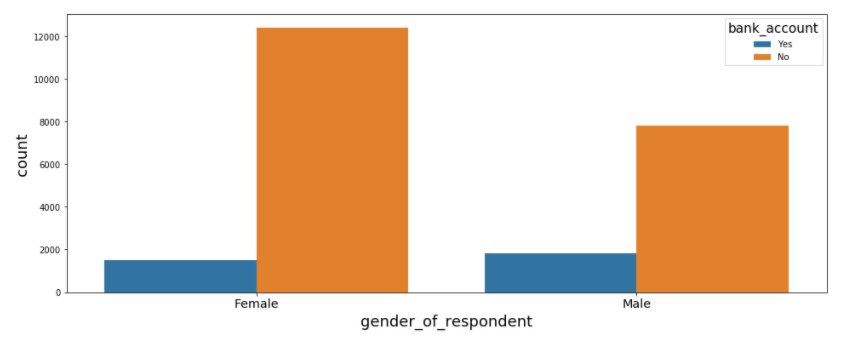
In the above plot, we try to compare the target variable (bank_account) against the gender_of_respondent. The plot shows that there is a small difference between males and females who have bank accounts (The number of males are greater than females). This prooves our assumption that femalse have less chance to have bank accounts.
#Explore cellphone_accesst vs bank account
plt.figure(figsize=(16, 6))
sns.countplot('cellphone_access', hue= 'bank_account', data=data)
plt.xticks(
fontweight='light',
fontsize='x-large'
)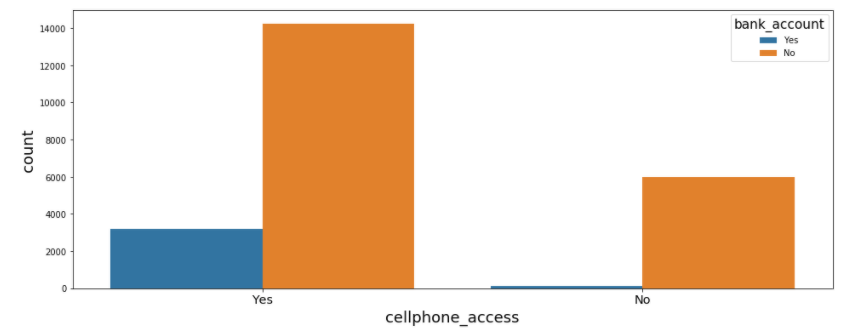
The cellphone_access plot shows the majority of people who have cellphone access, don't have bank accounts. This proved that people who have access to cellphone have a lower chance to use bank accounts. One of the reasons is the availability of mobile money services which is more accessible and affordable especially for people living in rural areas.
#Explore 'education_level vs bank account
plt.figure(figsize=(16, 6))
sns.countplot('education_level', hue= 'bank_account', data=data)
plt.xticks(
rotation=45,
horizontalalignment='right',
fontweight='light',
fontsize='x-large'
)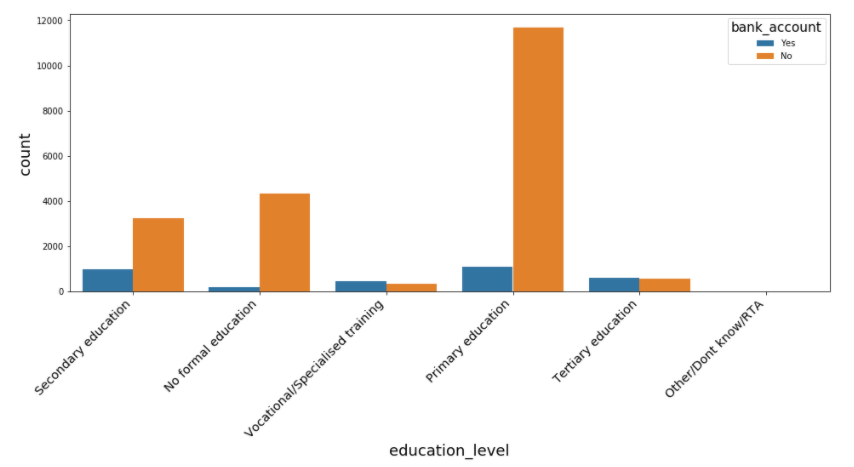
The education_level plot shows that the majority of people have primary education and most of them don't have bank accounts. This also proves our assumption that people with lower education have a lower chance to have bank accounts.
#Explore job_type vs bank account
plt.figure(figsize=(16, 6))
sns.countplot('job_type', hue= 'bank_account', data=data)
plt.xticks(
rotation=45,
horizontalalignment='right',
fontweight='light',
fontsize='x-large'
)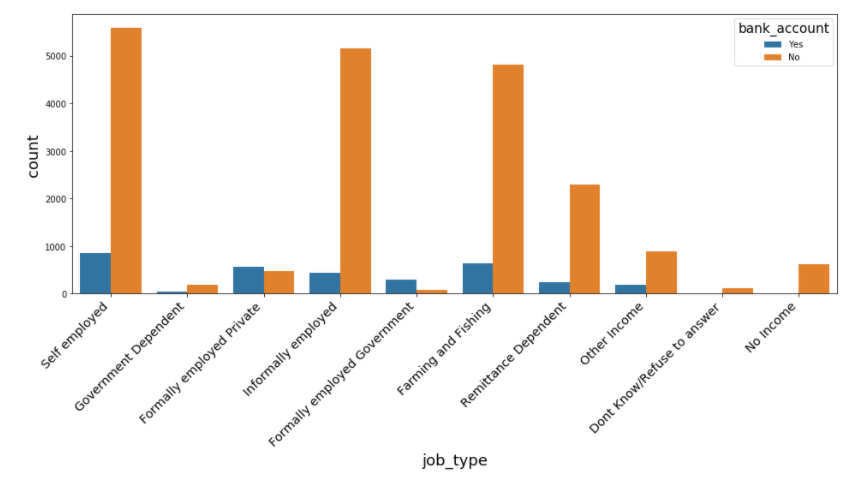
The job_type plot that the majority of people who are self-employed don't have access to the bank accounts, followed by informally employed and farming and fishing.
Now you understand important steps you can take while trying to explore and find insights and hidden patterns in your dataset. You can go further by comparing the relationship among independent features presented in the dataset.
But what if you have a dataset with more that 100 feature (columns)? Do you think trying to analyze each individual feature one by one will be the best way? Having many features in your dataset means it will take a lot of your time to analyze and find insights in your dataset.
The best way to solve this problem is by using a Python package called a data profiling package. This package will speed up the EDA steps.
Data Profiling Package
Profiling is a process that helps you in understanding your data and pandas profiling is a python package that does exactly that. It is a simple and fast way to perform exploratory data analysis of a Pandas Dataframe.
The pandas df.describe() and df.info() functions are normally used as a first step in the EDA process. However, it only gives a very basic overview of the data and doesn't help much in the case of large data sets. The pandas profiling function, on the other hand, extends the panda dataframe with df.profile_report() for quick data analysis.
Pandas profiling generates a complete report for your dataset, which includes:
- Basic data type information
- Descriptive statistics (mean, median, etc.)
- Common and extreme values
- Quantile statistics (tells you about how your data is distributed)
- Correlations (show features that are related)
How to install the package
There are three ways you can install pandas-profiling on your computer:
You can install using the pip package manager by running:
pip install pandas-profiling
Alternatively, you could install directly from GitHub:
pip install https://github.com/pandas-profiling/pandas-profiling/archive/master.zip
You can install using the conda package manager by running:
conda install -c conda-forge pandas-profiling
After installing the packagee now you need to import the package by writing the following codes:
#import the package import pandas_profiling
Now let's do the EDA using the package that we have just imported. We can either print the output in the notebook environment or save it to an HTML file that can be downloaded and shared with anyone.
# generate report eda_report = pandas_profiling.ProfileReport(data) eda_report
In the above codes. we add our data object in the ProfileReport method which will generate the report.
If you want to generate a HTML report file, save the ProfileReport to an object and use the to_file() function:
#save the generated report to the html file
eda_report.to_file("eda_report.html")Now you can open the eda_report.html file in your browser and observ the output generated by the package.
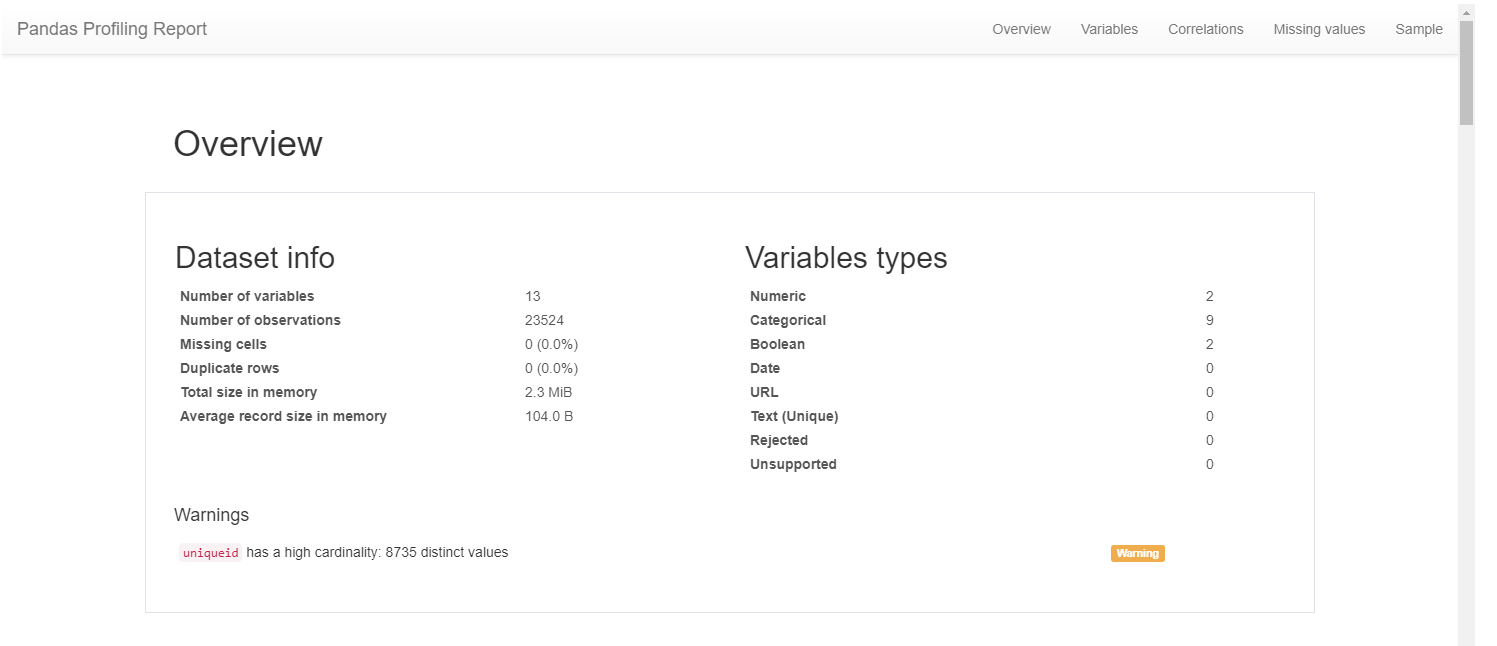
The above image shows the first output in the generated report. You can access the entire report here.
Conclusion
You can follow the steps provided in this article to perform EDA on your dataset and start to discover insights and hidden patterns in your data. Keep in mind that each dataset comes from a different source with different data types, which means you will need to apply a different way to explore your data when the dataset contains e.g. time series or text data.
If you learned something new or enjoyed reading this article, please share it so that others can see it. Feel free to leave a comment on the discussion boards. Till then, see you in the next post!
About the author
Davis David is Zindi Ambassador for Tanzania, as well as Data Scientist and CEO at ParrotAI. He is a public speaker, a teacher and a writer in the field of AI. You can get in touch with Davis on LinkedIn or Twitter to talk about AI and machine learning in Tanzania. This article first appeared on Medium.