
Task Mate Kenyan Sign Language Classification Challenge
'/%3e%3c/defs%3e%3cpath fill='%23fff' d='M-120-80h240V80h-240z'/%3e%3cpath d='M-120-80h240v48h-240z'/%3e%3cpath fill='%23060' d='M-120 32h240v48h-240z'/%3e%3cg id='b'%3e%3cuse xlink:href='%23a' stroke='%23000'/%3e%3cuse xlink:href='%23a' fill='%23fff'/%3e%3c/g%3e%3cuse xlink:href='%23b' transform='scale(-1 1)'/%3e%3cpath fill='%23b00' d='M-120-24v48h101c3 8 13 24 19 24s16-16 19-24h101v-48H19C16-32 6-48 0-48s-16 16-19 24z'/%3e%3cpath id='c' d='M19 24c3-8 5-16 5-24s-2-16-5-24c-3 8-5 16-5 24s2 16 5 24'/%3e%3cuse xlink:href='%23c' transform='scale(-1 1)'/%3e%3cg fill='%23fff'%3e%3cellipse rx='4' ry='6'/%3e%3cpath id='d' d='M1 5.85s4 8 4 21-4 21-4 21z'/%3e%3cuse xlink:href='%23d' transform='scale(-1)'/%3e%3cuse xlink:href='%23d' transform='scale(-1 1)'/%3e%3cuse xlink:href='%23d' transform='scale(1 -1)'/%3e%3c/g%3e%3c/svg%3e)

All thanks to @ZINDI for hosting this challenge,I was able to secure 1st place in this interesting competition.
I will not share my solution code, But instead of I will share my winning approach .
--------------------------------------------------------------------------
Here is the overview of my pipeline :
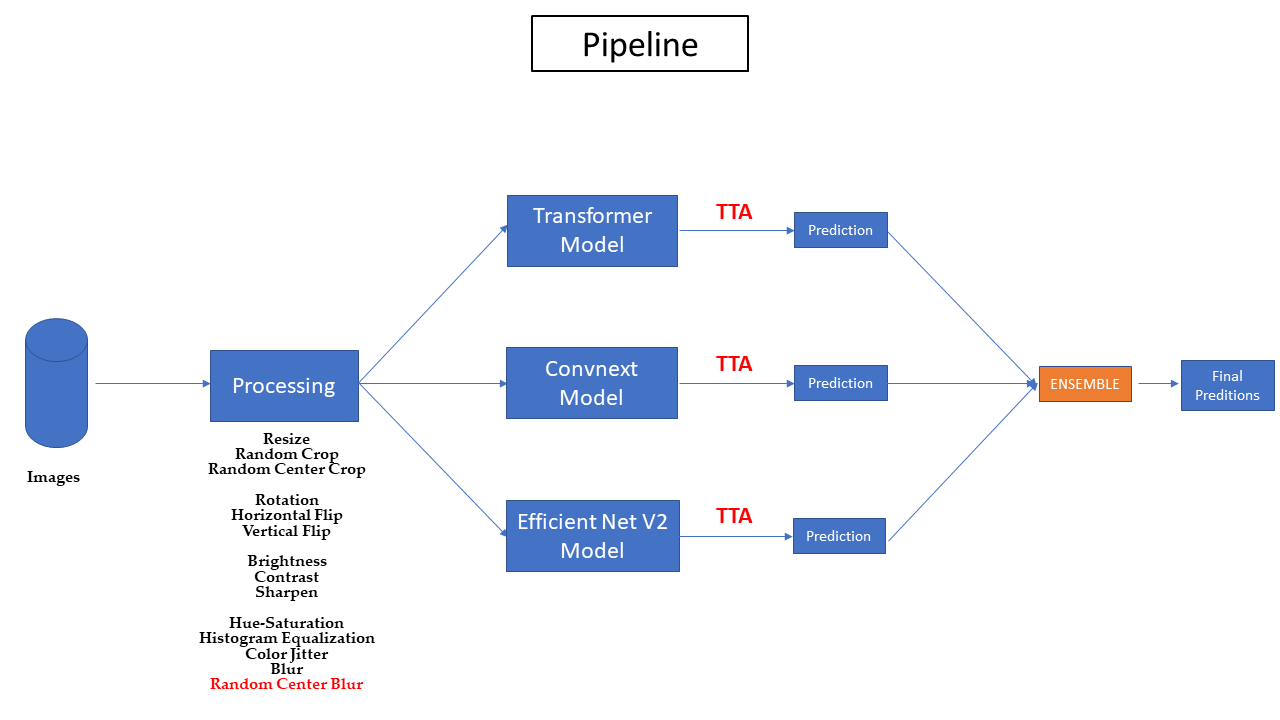
--------------------------------------------------------------------------
SUMMARY
Final submission :
- Public: 0.084 (1st place ) || Private: 0.1324 (1st place )
Image Sizes :
- i used different image sizes . [(384x384),(400x400),(448x448)]
Models Used :
- Transformers
- EfficientNet V2
- Convnext
Training pipeline :
- Batch Size : i used different Barch sizes . [8,6,4]
- Split : Stratified KFold with K=10
- LR : From 5e-5 to 1e-4
- From 7 to 12 epochs
- Loss : CrossEntropyLoss
Data Augementation :
I used Heavy Data Augmentation in this challenge [They're are mentioned in the Pipeline.Processing].
But the one that really makes a difference was Random Center Crop .

--------------------------------------------------------------------------
Final Submission Selection :
My plan is to choose one submission with setting weights referring to LB Scores , and another based on CV scores.
Both Scored 0.084 On Public and give me 1st place in the private lb with some small differences .
--------------------------------------------------------------------------
@devnikhilmishra , @kiminya The ball is on Your court now 😎
NOTE : how to add image in ZINDI Discussion ? just drag and drop
congratulations @Azer on the great performance. Thanks to Zindi for organizing this challenge.
Thanks for sharing @ASSAZZIN, this is a great approach, very explanatory too.🤝
Amazing technique !!! @ASSAZZIN Thank you for sharing this great technique. You guys are making this platform more insteresting to learn. Waiting to hear more from others on their own kinds of methods used in this great competition. This is an amazing challenge coming from Zindi, i must say.
Cheers to all.
Wow, congrats @ASSAZZIN!
Congrats @ASSAZZIN. You did great.
I was amazed by how great transformers seemed to perform in this competition. But sadly, I had clocked out my gpu quotas when I noticed their perfomrmances.
I would like to ask a question about the Convnext model. Which variant did you used and performed best ? Small, base or large ? (I settled with the Base variant; the larger ones weren't too much happy with the way I setup my pipeline xD)
Thanks @Muhamed_Tuo !
Convnext Xlarge Perform very well with :
Wow amazing. The best I could attain with a single model was with the Base:
Overall there seems to be a consistency between CV and Private LB.
Congratulation;
Your choice of model is similar to mine, I used Transformer models (cswin, swin and volo) and efficientnet (b4,b5 and b6). I am actually new to this platform and still learning how to do some basic ensemble (I resolve to simple averaging). My augmentation is not as detailed as yours while I did not include TTA.
I used only 384x384 image size as well as the variant of the transformer models pretrained with imagenet22k.
Indeed, I thank @zindi for such a competition that gives me chance to explore.