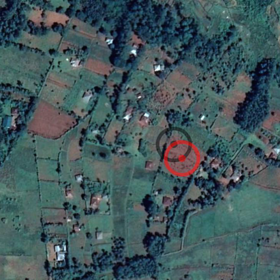
Lacuna - Correct Field Detection Challenge
Helping East Africa
$10 000 USD
Completed (almost 5 years ago)
Prediction
Earth Observation
635 joined
110 active
Start
Mar 26, 21
Close
Jul 04, 21
Reveal
Jul 04, 21

Is this solvable?
Help · 20 Apr 2021, 20:24 · edited 42 minutes later · 8
I wonder if this is a plausible problem. I get MAEs bellow 0.3 in validation, however, when predicting test images seems very difficult to get below 0.69, the same value that gives a submission with all 0s.
Just to make sure and not to waste time.
You have to put in $40,000 work to get your $4,000 ... this is my first time competing and I submitted a very simple network just to test and afterwords built a few more that I was sure would do better. The simple network still has the best score by far. It seems pretty difficult as you notice. Also those images!? They seem very low quality or maybe I am just not getting it, but I am unable myself to visually identify the fields. I'm using the supplied starter notebook to draw them but it does not make sense.
I think it's difficult in ML to generate the distance point relationship (especially with this data).
however, read this topic: https://zindi.africa/competitions/lacuna-correct-field-detection-challenge/discussions/5776
I am starting to think that this problem is unsolvable, I iterated over many approaches and none of them beats starternote notebook.
Exactly. Just have a look at the leaderboard, the difference between the first and the all 0s submission is too small, it must be around MAE=0.01. The variables range from -1 to 1, if I remenber corretly, and a MAE of 0.01 in that range is just 0.5% difference. It is true that most of the labels must be closer to 0 than -1 or 1, but this problem is not worth your time
I've made good progress, both conceptually and in implementation, and get MAE below 0.1 nowadays. The training sample is small, so I use all data and use the test as a type of hold out and submit to get a type of validation score. But no matter what MAE I get in training sample, when I submit I get something that is worse than all zeros. I think, or maybe hope, the test data that report MAE back to us is dirty or not representative or small in comparison to full test data that will eventually be used.
Yes, that is true, locally you can get pretty good results, but not with the leaderboard public test set.
I've been running into this a while now. I either should split the limited data I have and make my own validation set or play in the dark and submit the model I think will work. Some info on how big the actual test sample is and on how big the one being used to construct the leaderboard will be helpful.
Anyhow, what would your thoughts be on using your own validation sample and ignoring the leaderboard for this one?
I've submitted a few models and kept track of the score both locally and on Zindi - the correlation is -40%.