Lacuna - Correct Field Detection Challenge

Introduction
The purpose of this post is to explain how the data was annotated. We hope that this would help you better understand the problem and give you insights for your solutions.
Problem Description
We have a set of GPS coordinates corresponding to the centers of maize fields. There were some issues in the data collection process which sometimes resulted in GPS coordinates that do not precisely coincide with their correct maize field centers. The errors in the GPS coordinates are due to recording on the edges of the field rather than the center, or in the house which owns the farm, or under the shade of a nearby tree, or even on the main road leading to the farm.
The problem we are trying to solve is to correctly identify the original field centers given the GPS coordinates.
Annotation Process
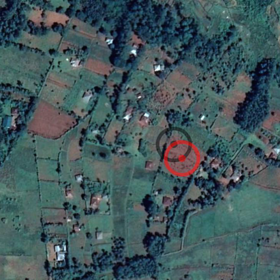
The GPS coordinates are projected on the map as shown in the figures below. Two target icons are drawn on the map; black indicates original position and red indicates corrected position. The area of these icons is calculated from the “plot size” variable but may not exactly match its size. Note that the icons are always circular but the field itself may be an elongated rectangular stretch or even triangular. Also, the corrected (red) field location may be somewhat far from the original (black) location.
 📷
📷 📷
📷 📷
📷Challenges
The figures above demonstrate some of the challenges in this problem.
The image resolution in the competition data is lower than these figures, making it harder to identify the fields. We couldn’t use the same high resolution images due to licensing issues.
Furthermore, sometimes there are multiple possible candidate target fields and the annotator has to make a best guess based on size and proximity of the field. This is captured by the “Quality” variable in the data.
Moreover, some field workers record multiple data points in the same spot making plot size the only distinguishing variable.
What about the leaderbord test data ? At least testing has guaranteed correct annotation, right ?
The annotation process is the same for both train and test data.
Thanks for clarifying, but is that the right evaluation ?
I agree that we should utilize all kind of data points with different qualities in training, but one would expect testing to have good quality annotation, even for your own use, is a model that gives you the lowest MAE on a test set with (1-2-3) quality points usefull ? shouldn't your evaluation be according to accurately annotated data ?
Sorry for the late reply. We are evaluating on all the quality levels because all of them happen in real life and we are interested in solutions that address them.
Thanks for responding,
I still think that is a wrong reason to use all qualities for evaluation, it is this simple, yes all quality levels happen in real life, some of them (maybe 1/2) have mistakes, we won't throw those parts we would like to utilise that data to produce our models (in training), but the evaluation should be only on level 3 quality (you learn from all qualities but expect a good model to produce annotations as close to perfect/correct as possible.
Please explain if I give you a model that is able to produce the same patterns of mistakes seen in training on the test set, how is that usefull to your use case ? how is that usefull in any case ?
Thanks Karim - this helps a lot.
Can you explain a bit more about the Quality. Does low quality mean there are multiple fields around the target?
Then - note that we are not trying to accurately find the most fields here, we are trying to minimise MSE.
From the leaderboard it seems to get a low MSE you can just submit zeros.
The problem with MSE is that is penalises you heavily if you are wrong on a single field. Thus if you get 19/20 fields correct but make a big mistake on that last field, you will probably loose to somebody who just submit a bunch of zeros and did not find a single field correctly. Maybe the score should be a +1 if you are close to the field center and 0 otherwise rather than MSE. But hindsight is a perfect science and it is probably wrong to change the scoring now. Also, as Baptism pointed out, we will probably crack this one eventually.
You are welcome skaak and thanks for your suggestion. The problem with your idea is that the defintion of "close to the field center" isn't clear and it needs a detection model itself espicially that the fields have different areas and shapes.
Therefore, the metric of the competition is MAE not MSE so as not to penalize more the large errors.
Thanks - my mistake! I thought it was MSE but I see it is MAE. Yes MAE is best for this.
While working on a project that required labeling a large set of images, I discovered a image labeler / data annotator service. They offer services as an image labeler or data annotator. Their platform seemed user-friendly and their approach to data labeling appeared both efficient and accurate, which could be really beneficial for projects needing precise image data categorization.