Building machine learning models is an experimental process that requires many iterations. You change different model parameters or data preprocessing steps at each iteration to obtain an optimal model. Keeping track of the processing steps and the parameters at each iteration is vital - failure to do this leads to repetition of these steps, which wastes precious time and processing power.
Tracking your datasets and models also allows for comparison between different experiments. Information about the models and datasets is referred to as metadata. In this article, we’ll explore the idea of experiment tracking and metadata storage in machine learning, using Layer. We’ll also discuss why they are essential in your machine learning workflow.
Let’s dive in.
What is experiment tracking?
Building machine learning models involves various steps such as data processing and model definition. Each step could result in new data and model versions. Furthermore, you may also try different parameters at each step. Other information you may be interested in tracking in your experiments include:
- Model evaluation metrics
- Model evaluation charts
- Model code
- Sample predictions.
- Images (e.g. for computer vision projects)
The process of tracking all this information is known as experiment tracking.
What is a machine learning metadata store?
Success in experiment tracking requires a tool that can keep track of all the information mentioned above and store it, i.e., a metadata store. A metadata store saves data that is generated in the process of building machine learning models. Storing experiment metadata enables comparability and reproducibility of ML experiments.
Using Layer as a metadata store
Layer is an MLOps metadata store that lets you track models and datasets and their resulting metadata in a central repository. Layer also offers semantic versioning, extensive artifact logging, and dynamic reporting with seamless local and cloud integration.
Layer is used by either individuals (free to use) or organisations to manage machine learning projects. Layer organisations enable a team to collaborate on different projects. The projects can either be public or private.
The Layer SDK is an open-source metadata store that allows data scientists to log, store, view, and compare different experiments. Layer provides a fully managed solution that you can start using immediately by visiting app.layer.ai.
Layer is different from other metadata stores because it allows for smooth local and remote development integration. For instance, you can use your local resources to run a few simple experiments and quickly transition to using Layer infrastructure to train the model with more powerful computing resources. Layer logs and versions metadata whether you are using local or remote mode.
Some of the items you can log using Layer include:
- Charts
- Images
- GIFs
- Markdown
- Model metrics
- Model parameters
- DataFrames
- Primitives
- Gradio/Streamlit Apps

Example logging on the Layer UI
Layer automatically versions datasets and models at each run. Further, Layer allows you to log data about your data. For instance, you may be interested in recording:
- The data source
- The data description
- Summary statistics of the data using charts
Collaboration is a crucial part of any model development process. Documenting projects is important because it makes it easy for other people to work together on the project. It also makes it easy for you to return to the project in the future. For this reason, Layer provides project pages to make it easy to document your project. Project documentation is provided using a README file. The file should be saved in the same folder as your project. When you initialize your project, Layer reads this file and updates your project’s page. Layer also allows for dynamic reporting. This is done by pasting links to your Layer model, dataset, charts, etc in the README. Layer displays and links these entities on the Layer project page.

The Layer community page provides multiple example projects and datasets to get you started quickly. There are also other examples on the GitHub repo.

Tracking experiments with Layer
You can easily add Layer to new or existing ML projects. Layer provides a few Python decorators that result in a rich model and data registry. Let’s mention a couple of them:
@model()
Wrapping your model training function with the model decorator will store and version the resulting model to Layer. This helps you manage the lifecycle of your model with semantic versioning. The model can then be fetched and used for making predictions immediately.
@dataset()
Adding the dataset decorator to your data creation functions saves the resulting data to Layer. Layer will semantically version the data making your pipelines reproducible. Layer supports tabular and image datasets.
@assert()
Testing in machine learning ensures that you have error-free pipelines. To help you to achieve this, Layer has created a list of assertions. You add the appropriate assertion decorator in your code to add a behavioural test to your ML model or a unit test to your dataset.
Apart from decorators, Layer provides other functions. These are:
layer.log()
Log metrics, tables, images, markdown/HTML content, and everything from your machine learning experiment. Then compare your results with your previous versions of your experiments.
layer.run()
Layer is an advanced ML metadata store and pipeline runner. You can use Layer infrastructure to seamlessly build your datasets, train your models, and store your resulting model and dataset artefacts. This is especially useful when:
- Your training data is too big to fit in your local machine
- Your model requires special infra like a high-end GPU that is too expensive to provision permanently
With that information at hand, let’s look at how we can track a simple HistGradientBoostingClassifier model. First, ensure that you have the latest version of the Layer SDK:
pip install -U layer
Next, you need to authenticate your Layer account and initialize a new project.
import layer
layer.login()
layer.init("experiment-tracking")In this illustration, we generate a simple dataset with Scikit-learn to keep the example focused on the model part. However, you can also save, track, and version datasets with Layer. In the example below, we:
- Store the project’s description with `layer.log`
- Save the model parameters
- Log the average precision score and the ROC_AUC_score
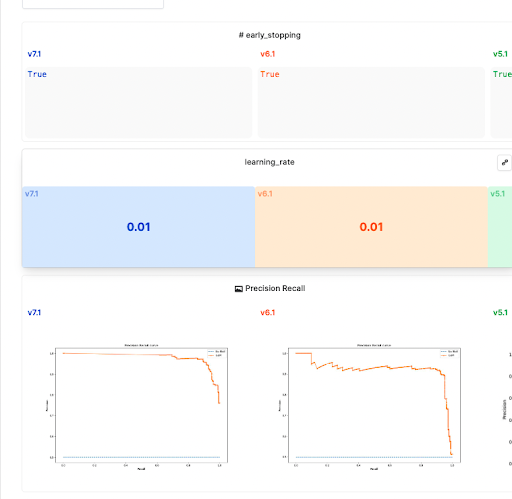
- Save the ROC Curve and Precision Recall curve
View the example notebook here.
Finally, we run the training function on Layer infrastructure by passing it to the layer.run function. If you would like to run the function locally, you would just call it normally, that is train(). Layer will still store all the metadata to your Layer account whether you are running on local or remote mode.
Conclusion
In this article, you have learned what experiment tracking is and how you can implement it in your project. We have also covered:
- What is a metadata store
- How to use Layer to keep track of your machine learning projects’ metadata
- How to improve your projects with dynamic project documentation
Here are some resources to quickly get you started with Layer:
- How to add datasets in Layer
- How to add models in Layer
- Layer best practices
- Experiment tracking project
- Layer SDK
Visit layer.ai to start building now! Don’t forget to join the Slack community, and follow them on Twitter and LinkedIn for resources, events, and much more.
If you’re interested in using Layer to track your experiments for a Zindi competition, check out the Laduma Analytics Football League Winners Prediction Challenge currently live on Zindi. We have included a guide to using Layer for this dataset.