Join ICLR Workshop Challenge #2: Radiant Earth Computer Vision for Crop Detection from Satellite Imagery winner Karim Magdy Amer (KarimAmer) as we talk about his winning deep learning solution and why he works in AI.
Hi Karim, please introduce yourself to the Zindi community.
I am a Computer Vision researcher at Nile University in Egypt, applying deep learning in different aspects in these last four years, and focusing recently on satellite imagery and agriculture.
Tell us a bit about your data science journey.
I was drawn to AI research and deep learning as a way to help people and work on applications from different fields like health care and agriculture while learning new perspectives from experts from these fields.
I previously worked as a research assistant with the Ubiquitous and Visual Computing Group at Nile University, where I published several papers (Karim Amer) about satellite image analysis between 2016 and 2018. In 2019, I became a research intern at Siemens Healthineers Technology Center, NJ, USA where I worked on development of cutting edge segmentation models that can be used in multiple clinical applications.
What do you like about competing on Zindi?
I always look forward to working with fellow Zindians to solve more real life problems using AI algorithms. I am grateful to the team at Zindi for the comprehensive review stage of the competitions, I am really thankful to you guys for doing that. In terms of improving the platform, having some dedicated computational resources for competitors will increase the level of innovation.
Tell us about your solution for the Radiant Earth Crop Detection Challenge.
I used a deep neural network of multiple convolutional and recurrent layers to classify the crop of input fields. The model benefits not only from the field information but also from the surroundings. To be more specific, a small patch is cropped around each field (mostly wider than field size) alongside a patch mask with ones at pixels that belong to the field, and I used both as inputs for the model.
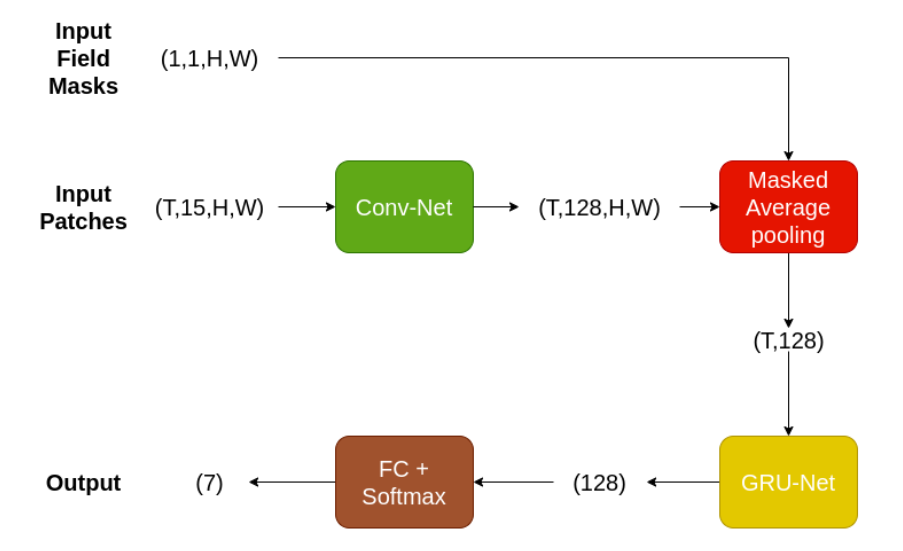
The first key success to make it work was to apply different augmentations including flipping, rotation, random cropping, mixup and time augmentation. The second key success was using a bagging ensemble by training the model 10 times on different 85% subsets of the training data.
You can watch Karim present his winning approach in more detail here: Part 1 | Part 2
What do you think set your approach apart?
Firstly, understanding the data and having a good local validation strategy is crucial to build a generalisable model.
Secondly, using heavy augmentation is a must when training deep learning models on small datasets.
Finally, ensembling stabilises the results in testing.