In this article, we will go over a few techniques that you should know as data scientists to be better developers and prepare for production-level code. You will learn how to write clean and modular code, improve your code's efficiency, document effectively, and use version control.
These are all essential skills to develop as a programmer and will really help in implementing production solutions. Also, data scientists often work side-by-side with software engineers, and it's important you work well together. This means being familiar with standard practices and being able to collaborate effectively with others on code.
Let's walk through each of these practices and learn how they're applied as a data scientist. Without further ado, let's get started.
Writing Clean Code
As a data scientist, It’s important to note that when working in industry, your code could potentially be used in production. Production code just means code that is run on production servers, For example, code running on software products like Google or Amazon are considered as production code. Ideally, code that's being used in production should meet several criteria to ensure reliability and efficiency before it becomes public. For one, the code needs to be clean.
Code is clean when it's readable, simple and concise. Here's an example in plain English of a sentence that is not clean.
One could observe that your shirt has been sullied, due to the orange colour of your shirt that appears to be similar to the colour of a certain kind of juice.
This sentence is terribly redundant and convoluted. This can be rewritten as,
It looks like you spilt orange juice on your shirt.
and accomplish the same thing because it's much more concise and clear.
Writing clean code is very important when you’re on a team that's constantly iterating over its work. This makes it much easier for yourself and others to understand and reuse your code. Here are some helpful tips to help write clean code:
Use meaningful variable names
- Be descriptive and imply type - E.g. for booleans, you can prefix with is_ or has_ to make it clear it is a condition.
- Be consistent but clearly differentiate - E.g. score_list and score is easier to differentiate than scores and score.
- Avoid abbreviations and especially single letters - (Exception: counters E.g i,j and common math variables E.g X, y)
- Long names != descriptive names - You should be descriptive, but only with relevant information. E.g. good function names describe what they do well without including details about implementation or highly specific uses.
Use whitespace properly
- Organize your code with consistent indentation - the standard is to use 4 spaces for each indent.
- Separate sections with blank lines to keep your code well organized and readable. etc
Here's an example to illustrate: You want to write a program to iterate through your stocks and buy it if the current price is below or equal to the limit price you computed. Otherwise, you put it on a watchlist. Examine both codes to see which one of them is clean and otherwise.
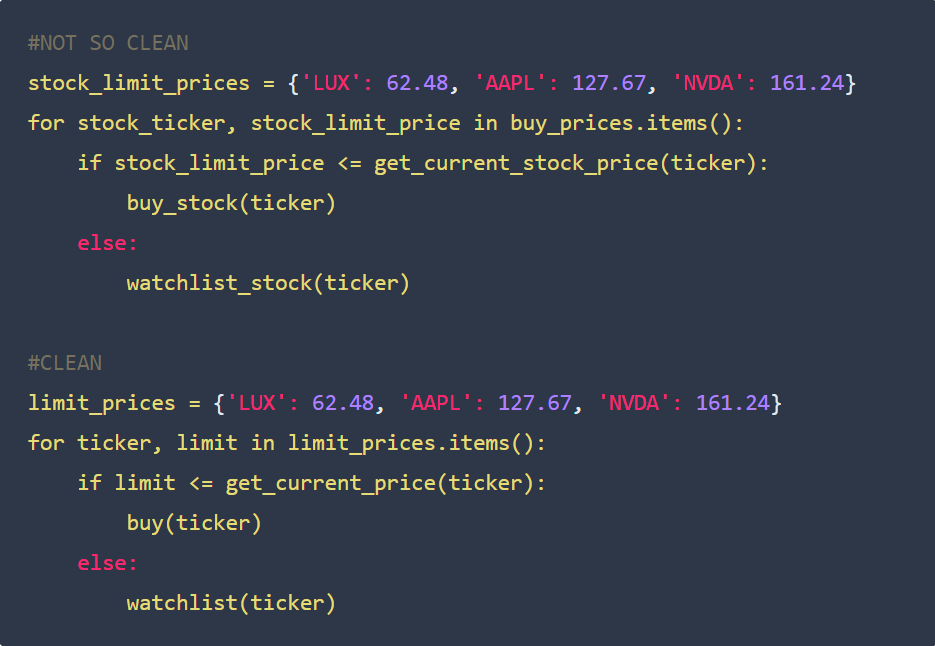
Writing Modular Code
In addition to being clean, your code should be modular. Meaning, your program should be logically broken up into functions and modules. In programming, a module is just a file. Similar to how you can encapsulate code in a function and reuse it by calling the function in different places, you can encapsulate code within a module or file and reuse it by importing it in other files.

It allows you to quickly find a relevant piece of code and you can often generalize these pieces of code to be reused in different places, to prevent yourself from writing extra unnecessary lines of code.
Code Refactoring
When you first sit down to start writing code for a new idea or task, it's easy to pay little attention to writing good code and focus more on just getting it to work. So, your code typically gets a little messy and repetitive at this stage of development. For example, it could be difficult to know exactly what functions would best modularize the steps in your code if you haven't experimented enough with your code to understand what these steps are. That's why you should always go back to do some refactoring after you've achieved a working model.
Code refactoring is a term for restructuring your code to improve its internal structure without changing its external functionality.
Sometimes it may seem like a waste of time but refactoring your code consistently not only makes it much easier to come back to it later, it also allows you to reuse parts for different tasks and learn strong programming techniques along the way.
Here's a quick example, say you want to replace the spaces in the column names of a dataset df with underscores to be able to reference columns with dot notation. Here's one way you could've done it.

The code above can be refactored to be

Sleek right?
Writing Efficient Code
When you refactor, it's important to improve the efficiency of your code in addition to making it clean and modular. There are two parts to making code efficient.
- Reducing the time it takes to run
- Reducing the amount of space it takes up in memory
Both can have a significant impact on a company or product. However, you should note that how important it is to improve efficiency is context-dependent, slow code might not need to be optimized right away if it runs in production say once in a day for just a few minutes, on the other hand, code used to generate posts on a social media feed needs to be relatively fast since updates happen simultaneously.
This can be illustrated using the following example. Say you have two lists of books recent_books and coding_book and you need to get books that appear in both lists so you can have a list of recent_coding_books, here are two different codes that do the same thing.
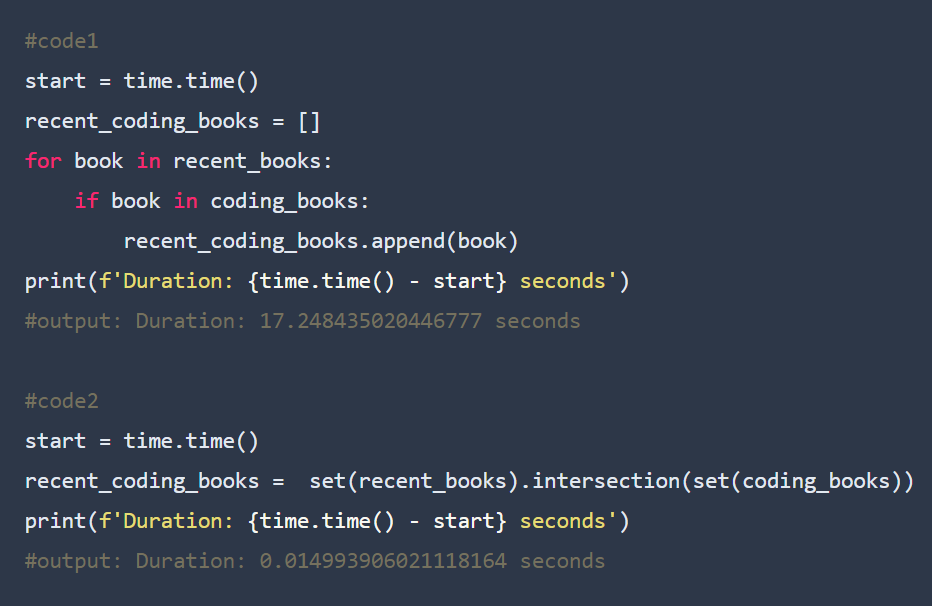
Wow, if you examine both codes carefully, you'll see by avoiding the use of a for loop we were able to perform the task about 1000X faster (0.014second compared to 17.248seconds).
Adding Meaning Documentation
Documentation is additional text or illustrated information that comes with, or is embedded in, the code of software.
Documentation helps clarify complex parts of your program, making your code easy for yourself and others to navigate and quickly conveying how and why different components of your program are used. There are several types of documentation you can add at different levels of your program.
- You can add documentation at the line level using in-line comments to clarify your code.
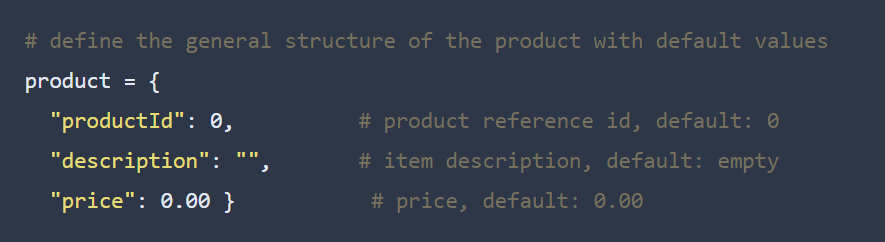
- Second, you can add documentation at the function or module level using docstrings to describe its purpose and details.

Finally, you can add documentation at the project level using various tools such as a readme file to document details about the project as a whole and how all the files work together, You can find a nice example of a detailed readme on Danfo.js GitHub page.
Using Version Control
Imagine a scenario where you trained a machine learning model on some set of parameters which gave a very good accuracy score of 87%, but like Oliver twist, you're still not satisfied and want to increase your model's score to 90%. After trying out a bunch of other things you can't seem to get 90% or even come close to your best score of 87%, You decided to go back to the version that gave a score of 87% but unfortunately, you already forgot the parameters that gave that score. What do you do now? (shut down and go to sleep? Lol).

This can easily be avoided by using a distributed version control system like git, it enables you to track changes in source code and in any set of files. git's support for distributed workflow enables teams to easily work on a project simultaneously. Every developer is strongly advised to be proficient in using git. I'll recommend this tutorial from FreeCodeCamp to learn the basics of Git and GitHub.
I'm sure you've learnt some valuable skills that will help you in all of your future programming work as a data scientist. Being able to write code that's clean, modular, and efficient makes you a strong developer, and allows you to easily reuse and share your code. and using effective documentation and version control are such important practices in industry that will really help you in future projects.
Thanks for reading.
About the author
Paul Okewunmi is a data science, machine learning, and Python enthusiast who has recently emerged as Mr. Algorithm in the DSN 2020 #AIBootcamp. He not only strives to be the best in the data science community of Nigeria, but he is also incredibly invested in helping others through knowledge sharing. He can be reached on Twitter @paul_okewunmi.
You can read the original blog post here.