‘Attention Is All You Need’
New deep learning models are introduced at an increasing rate, and sometimes it’s hard to keep track of all the novelties. In this article we will talk about transformers, a type of neural network architecture that has been gaining popularity, and include some guidance on implementation using a notebook.
In this post, we will address the following questions related to transformers:
- why do we need transformers?
- transformer and its architecture in detail.
- text classification with transformers
- useful papers in dealing with transformers
Why do we need the transformer?
Transformers were developed to solve the problem of sequence transduction, or neural machine translation. That means any task that transforms an input sequence to an output sequence. This includes speech recognition, text-to-speech transformation, etc.
For models to perform sequence transduction, it is necessary to have some sort of memory.
The limitations of long-term dependencies:
A transformer is an architecture for transforming one sequence into another one with the help of two parts (encoder and decoder), but it differs from existing sequence-to-sequence models because it does not imply any recurrent networks (GRU, LSTM, etc.).
The transformer architecture is well introduced in the paper Attention is All You Need; as the title indicates, transformer architecture uses the attention mechanism.
Let’s consider a language model that will predict the next word based on the previous ones:
Sentence: “Bitcoin is the best cryptocurrency.”
Here we don’t need an additional context , so obviously the next word will be “cryptocurrency”.
In this case RNN’s can sove the issue and predict the answer using the past information.
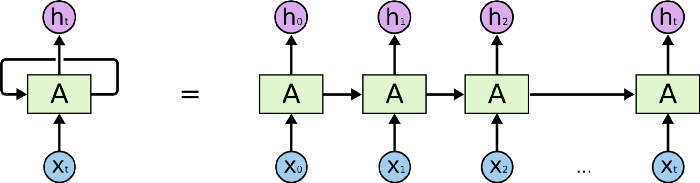
But in other cases we need more context. For example, let’s say that you are trying to predict the last word of the text:
Sentence: "I grew up in Tunisia, I speak fluent ..."
Recent information suggests that the next word is probably a language, but if we want to narrow down which language, we need context of Tunisia, that is further back in the text.
RNNs become very ineffective when the gap between the relevant information and the point where it is needed becomes very large. That is due to the fact that the information is passed at each step and the longer the chain is, the more probable the information is lost along the chain.
I recommend the article How Transformers Work, which talks in depth about the difference between seq2seq and transformer.
Transformer and its architecture in detail:
An image is worth a thousand words, so we will start with that!
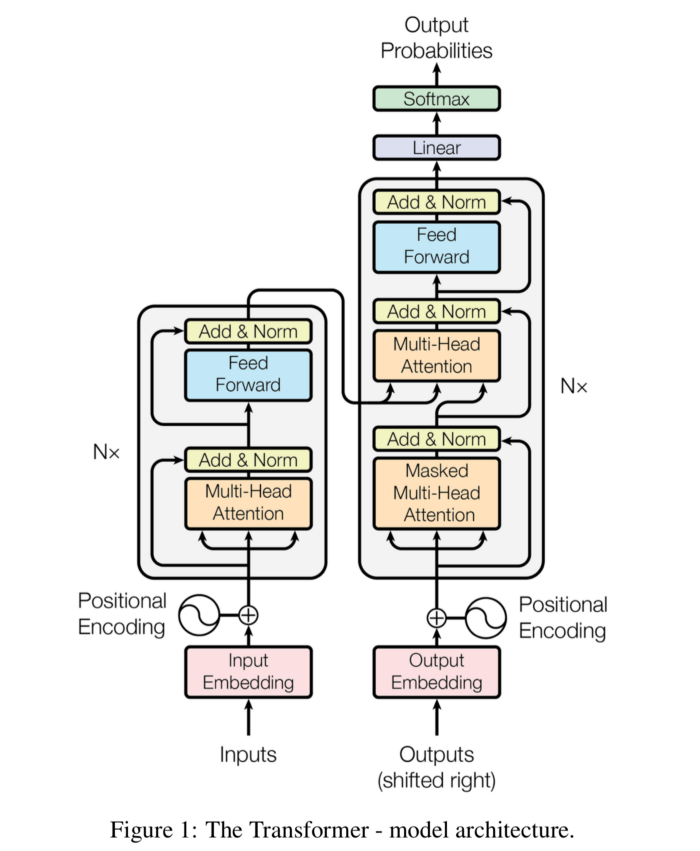
The first thing that we can see is that it has a sequence-to-sequence encoder-decoder architecture. Much of the literature on transformers uses this very architecture to explain transformers. But this is not the one used in Open AI’s GPT model (or the GPT-2 model, which was just a larger version of its predecessor). The GPT is a 12-layer decoder only transformer with 117M parameters.
The transformer has a stack of 6 encoders and 6 decoders, unlike seq2seq; the encoder contains two sub-layers: multi-head self-attention layer and a fully connected feed-forward network. The decoder contains three sub-layers, a multi-head self-attention layer, an additional layer that performs multi-head self-attention over encoder outputs, and a fully connected feed-forward network. Each sub-layer in encoder and decoder has a residual connection followed by a layer normalization.
All input and output tokens to encoder/decoder are converted to vectors using learned embeddings; these input embeddings are then passed to positional encoding.
The transformers architecture does not contain any recurrence or convolution and hence has no notion of word order. All the words of the input sequence are fed to the network with no special order or position as they all flow simultaneously through the encoder and decoder stack. To understand the meaning of a sentence, it is essential to understand the position and the order of words.
III - Text Classification using transformer with Pytorch implementation:
It is too simple to use the ClassificationModel from simple transformes:
ClassificationModel(‘Architecture’, ‘model shortcut name’, use_cuda=True,num_labels=4)
Architecture: Bert , Roberta , Xlnet , Xlm…
Shortcut name models for Roberta : roberta-base , roberta-large…
More details here
We create a model that classify text for 4 classes [‘art’, ‘politics’, ‘health’, ‘tourism’]
We apply this model in our previous project
Watch video here
And we integrate it in our flask application here
Here you will find a commented notebook:
- Setup environment & configuration
!pip install --upgrade transformers
!pip install simpletransformers
# memory footprint support libraries/code
!In -sf /opt/bin/nvidia-smi /user/bin/nvidia-smi
!pip install gputil
!pip install psutil
!pip install humanize importing libraries
- Importing Libraries
import psutil import humanize import os import GPUtil as GPU import numpy as np import pandas as pd from google.colab import files from tqdm import tqdm import warnings warnings.simplefilter('ignore') import gc from scipy.special import softmax from simpletransformers.classification import ClassificationModel from sklearn.model_selection import train_test_split, StratifiedKFold, KFold import sklearn from sklearn.metircs import log_loss from sklearn.metrics import * import re import random import torch pd.options.display.max_colwidth = 200 #choose the same seed to assure that our model will be reproducible def seed_all (seed_value) : random.seed (seed_value) # Python np.random.seed (seed_value) # cpu vars torch.manual_seed (seed_value) # cpu vars if torch.cuda.is_available () : torch.cuda.manual_seed (seed_value) torch.cuda.manual_seed_all (seed_value) # gpu vars torch.backends.cudnn.deterministic = True #needed torch.backends.cudnn.benchmark = False seed_all (2)
- Reading Data
import pandas as pd #We consider that our data is a csv file (2 columns : text and label) #using pandas function (read_csv) to read the file train=pd.read_csv()
- Verify the topic classes in the data
train.label.unique()
- train the model
label_cols = ['art', 'politics', 'health', 'tourism'] train.head() L=['art', 'politics', 'health', 'tourism'] # Get the numerical ids of coloumn label train['label']=train.label.astype('category') Y = train.label.cat.codes train['label']=Y # Print initial shape print(Y.shape) from keras.utils import to_categorical # One-hot encode the indexes Y = to_categorical (Y) # Check the new shape of the variable print (Y.shape) # Print the first 5 rows print (Y[0:5]) for i in range (len(l)) : train[l[i]] = Y[:,i] #using KFOLD Cross Validation is important to test our model %%time err=[] y_pred_tot=[] fold=StratifiedKFold(n_splits=5, shuffle=True, random_state=1997) i=1 for train_index, test_index in fold.split (train,train['label']): train1_trn, train1_val = train.iloc[train_index], train.iloc[test_index] model = ClassificationModel ('roberta', 'roberta-base', use_cuda=True,num_labels=4, args={ 'train_batch_size':16, 'reprocess_input_data': True, 'overwrite_output_dir': True, 'fp16': False, 'do_lower_case': False, 'num_train_epochs': 4, 'max_seq_length': 128, 'regression': False, 'manual_seed': 1997, "learning_rate":2e-5, 'weight_decay':0, "save_eval_checkpoints": True, "svae_model_every_epoch": False, "silent": True}) model.train_model (train1_trn) raw_outputs_val = model.eval_model{train1_val)[1] raw_outputs_vals = softmax(raw_outputs_val,axis=1) print(f"Log_loss: {log_loss(train1_val['label'], raw_outputs_vals)}") err.aprend(log_loss(train1_val['label'], raw_outputs_vals))
Output:
Log_Loss: 0.35637871529928816
CPU times: user 11min 2s, sys: 4min 21s,
total: 15min 23s Wall time: 16min 7s
Log Loss:
print("Mean LogLoss: ",np.mean(err))Output:
Mean LogLoss: 0.34930175561484067
raw_outputs_vals
Output:
array([[9.9822301e-01, 3.4856689e-04, 3.8243082e-04, 1.0458552e-03],
[9.9695909e-01, 1.1522240e-03, 5.9563853e-04, 1.2927916e-03],
[9.9910539e-01, 2.3084633e-04, 2.5905663e-04, 4.0465154e-04],
...,
[3.6545596e-04, 2.8826005e-04, 4.3145564e-04, 9.9891484e-01],
[4.0789684e-03, 9.9224585e-01, 1.2752400e-03, 2.3997365e-03],
[3.7382307e-04, 3.4797701e-04, 3.6257200e-04, 9.9891579e-01]],
dtype=float32)
- test our Model
pred = model.predict(['i want to travel to thailand'])[1] oreds = softmax(pred,axis=1) preds
Output:
array([[6.0461409e-04, 3.6119239e-04, 3.3729596e-04, 9.9869716e-01]],
dtype=float32)
We create a function which calculate the maximum probability and detect the topic
for example if we have 0.6 politics 0.1 art 0.15 health 0.15 tourism >>>> topic = politics
def estm(raw_outputs_vals): for i in range (len(raw_outputs_vals)): for j in range (4): if (max(raw_outputs_vals[i])==raw_outputs_vals[i][j]): raw_outputs_vals[i][j]=1 else : raw_outputs_vals[i][j]=0 return(raw_outputs_vals) estm(preds)
Output:
array([[0., 0., 0., 1.]], dtype=float32)
Our labels are :['art', 'politics', 'health', 'tourism']
so that's correct ;)
I hope you find it useful & helpful!
Download source code from our github.
Useful papers to read more about transformers:
Here a list of recommended papers to get in depth with transformers (mainly Bert Model):
- Cross-Linguistic Syntactic Evaluation of Word Prediction Models
- Emerging Cross-lingual Structure in Pretrained Language Models
- Finding Universal Grammatical Relations in Multilingual BERT
- On the Cross-lingual Transferability of Monolingual Representations
- How multilingual is Multilingual BERT?
- Is Multilingual BERT Fluent in Language Generation?
- Are All Languages Created Equal in Multilingual BERT?
- What’s so special about BERT’s layers? A closer look at the NLP pipeline in monolingual and multilingual models
- A Study of Cross-Lingual Ability and Language-specific Information in Multilingual BERT
- Cross-Lingual Ability of Multilingual BERT: An Empirical Study
- Multilingual is not enough: BERT for Finnish
Download all article files from our github repo.
Summary:
Transformers present the next front in NLP. In just a few years since its introduction, this new architectural trend has surpassed the feats of RNN-based architectures. This exciting pace of invention is perhaps the best part of being early to a new field like Deep Learning.
If you have any suggestions or a questions please contact NeuroData Team:
This article was written by Yassine Hamdaoui and first appeared on Medium. Code credits goes to Med Klai Helmi, NeuroData Data Scientist and Zindi Mentor.