OK, so you've learnt how to train an image classification model, and you try it out on a Zindi competition. Your score is decent, but there's a group of folks sitting above you on the leaderboard and you'd like to know what they have that you don't. Are they cheating? Is there a secret model type that only the Guild of Grand-Masters can access? Is it a conspiracy to avoid giving out prize money? No. Eking out that final 1% accuracy requires a whole bag of tricks. Today, we'll take a look at what some of the cool kids are using these days, and show you how you can start to climb towards the top in your next image recognition challenge.
A good baseline
Before we get fancy, we're going to assume you're already using some good practices in your model. Specifically:
Transfer learning: Starting from scratch means using lots of data, and that's not always available. Fortunately, we have many wonderful models available to us that have been trained on datasets like Imagenet. These pre-trained models already contain building blocks for recognizing all kinds of images, and we can re-purpose them for a new task. Pre-trained models are available through most deep learning libraries - in many, they're the default.
Data augmentation: Showing your model the exact same image multiple times is a good way to cause it to fixate on that specific image, rather than the idea behind it. With data augmentation, we create several similar images based on the initial example. Many libraries have data augmentation built in, but there are also stand-alone tools like Albumentations that can be added to your pipeline, and you can always dive in and get creative doing some of your own.

Data with augmentations applied - note the warping on some images
Cyclic learning rates, choosing a good learning rate, gradually unfreezing and training a pre-trained model... all techniques that have become mainstream in the past few years. You'll see fancy LR schedulers varying the LR, and everyone wants to invent the latest profile. Use whatever comes with your library - see the demo notebook where we use lr_find and fit_one_cycle methods from fastai.
We'll be looking at the MIIA Potholes Image Classification Challenge in the demo notebook accompanying this tutorial. We use the new (beta) fastai2 library to train a baseline using a pre-trained resnet34 model. This is similar to the starter notebook shared when the competition first launched. We train it for a few minutes and submit, to get a score of 0.81. This will be our starting point when looking at potential improvements.
The obvious sliders
There are some 'obvious' ways to get a better score, including:
- Training for longer
- Using a larger image size
- Trying a bigger network
Any of these will up your score, but they also increase training time. Before we deploy these easy wins, let's look at the less obvious options in our bag of tricks.
Progressive resizing

Popularized by the fastai course, progressive resizing involves training the network on smaller images first, and then re-training on larger and larger images. For some datasets this makes a big difference, and it's faster than just training more on large images from the start. Begin with 64x64 and work up, doubling each time, but think about whether this approach fits the problem. For potholes, can you even see them at lower resolutions?
Test-time augmentation
This is an easy win, but one that many people don't know about. Remember those data augmentations we talked about? What if you applied them to your test set, to get several different versions of each test image. You could make predictions for each, and average them. Simple, but effective! From our baseline score of 0.81, we can lower our score to 0.64 by replacing learn.get_preds(...) with learn.tta(...), letting fastai do the heavy lifting for us as it runs predictions on 8 augmented versions of each test image and combines the predictions.
As always, there are many ways to do this. For some competitions (CGIAR Computer Vision for Crop Disease for example), cropping in close to a larger image and making predictions for several sub-images helps a lot. For others, you need to be careful to keep the subject in view when doing your augmentation. Whichever method you choose, this is a good way to get better performance with very little effort.
Even more data augmentation
Let's talk about custom data augmentations. In some cases, there is something specific about the data that makes it worth thinking about how you'll be transforming the images before feeding them to your network. If it's satellite or aerial imagery, who cares about orientation? Flip those beauties vertically for extra fun. If it's pictures of sea creatures surrounded by large areas of gray background, crop them intelligently to zoom in on the features of interest. And looking at our example, what do we see? Lots of sky, lots of dashboard. Look at this transform:
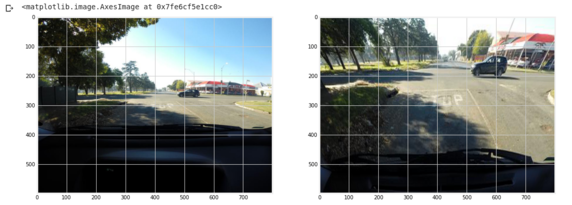
Transforming an image to exclude unnecessary parts
That winning entry in potholes, which I carefully screenshotted for my CV before sharing this tutorial, was based almost entirely on this single idea - there are no potholes in the sky!
Ensembles
If one model is good, more must be better! Training several different models and then averaging their predictions is another way to buy yourself some extra accuracy. This can get a little extreme, with vast ensembles of models, which is why you see many platforms moving towards compute/time limits. But the base idea is good. Here's an example from the winner of the SAEON Invertebrates Challenge, Rinnqd:
- resnet50 with size 224x224, 256x256, 512x512
- resnet152 with size 224x224, 350x350
- effcientnet b0 with size 224x224, 512x512
- efficientnet b4 with size 224x224
To make the most of an ensemble, you need variety. Train a few different architectures, or train some on different subsets of the data. I've had success with imbalanced datasets training one model on the common classes, another on the whole dataset and combining the predictions with adjustments made to get a better overall score.
Personally, I dislike the idea that more compute can buy you performance, and I like to see what can be done with a single model. If you've trained one model well, and done all the other work, then maybe you can try a few more and average. But have a heart for those of us without dedicated hardware, and don't just throw resources at the problem.
Research current hot topics
If there's lots of unlabeled data lying around for use, there are some other fun ways to boost your models. We won't go deeply into them now, but search around for the work being done on semi-supervised learning. Truly amazing stuff.
There's also lots of hype around strategies like MixUp, NoisyStudent, and so many more. Trying to implement one of these ideas is a good project, and might well improve your score. I don't have specifics to share, but keep an eye on what folks are talking about, and if something comes up enough that you start to wonder what it is then that's a sign that you should take a closer look and see if anyone has shared a tutorial or something about it yet.