At Zindi, we’re always working to make our challenges and our platform better - better at generating real-world solutions to pressing global problems, and better as a place to learn real-world machine learning and AI skills. That’s why we’re excited to introduce a brand-new evaluation approach and an upgrade to Zindi’s core scoring functionality: multi-metric evaluation. Multi-metric evaluation is a way to measure model performance across multiple dimensions, not just a single evaluation metric.
🌍 Real-world problems deserve real-world metrics
In the real world, machine learning models rarely succeed by being good at just one thing. Optimising for accuracy at the cost of other metrics makes for fragile, one-dimensional models, or misses key measures of success in other contexts. We need ways to measure the performance of our ML models holistically, and that’s where multi-metric evaluation come in.
Up until now, Zindi challenges have been restricted to a single error metric—Accuracy, RMSE, IoU, etc. But as machine learning tasks become more complex and multi-faceted, this just doesn’t cut it anymore. That’s why we’ve introduced multi-metric, multi-column evaluation.
Now, we can evaluate multiple outputs from a model at once - each with its own appropriate scoring metric - and combine them into a single leaderboard score.
For example, your model might be asked to:
- Predict a class label or attribute (evaluated with Accuracy),
- Reconstruct a polygon boundary (evaluated with Intersection over Union (IoU)),
- Estimate a continuous value (evaluated with RMSE or MAE),
- Or even generate a text summary (evaluated with ROUGE-F or WER).
Instead of reducing all that to a single measure, we now calculate the score for each target output, then combine them using a weighted average. Combinations of two or more existing error metric vastly expands the ways in which we can evaluate your performance in a challenge.
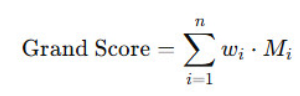
🛠️ Why we built this
✅ Robustness: Models shouldn’t game the metric. By evaluating across multiple outputs, we reduce the risk of “overfitting to the leaderboard” and reward more generalisable solutions - better for the end-user.
🧩 Holistic Understanding: We want to be able to reward models that don’t just do one thing well, but that perform well across all aspects of a task.
📊 Stable Leaderboards: Metrics like RMSE can be volatile, especially when data is skewed. Combining metrics provides a smoother, fairer scoring system.
🧪 Real-world Performance: In production, your model will be judged on more than accuracy. These metrics better reflect what matters in real deployment settings.
🚀 How it works on Zindi
Your submission file will now include specific columns for each error metric. Each column is scored with the relevant metric, and your final score is a weighted average of all of them.
For example, in our new Barbados Lands and Surveys Plot Automation Challenge, the leaderboard score is:
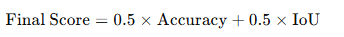
You need to get both the what and the where right to win.
🔢 Normalising scores
All metric scores are normalised before being shown on the leaderboard. This ensures fairness when a challenge includes both metrics you want to maximise (such as Accuracy) and metrics you want to minimise (such as Log Loss).

📈Regression problems
Regression metrics behave differently because a value of zero represents a perfect score, and the upper bound can grow indefinitely. To keep these metrics comparable, Zindi sets the x_max value to the metric score of the starter notebook on the leaderboard.
For rolling leaderboards such as the agriBORA Commodity Price Forecasting Challenge, the x_max values are taken from the starter notebook’s local validation scores instead, to ensure stable normalisation across weeks.
This means you are still aiming for a normalised leaderboard score close to 1 for regression tasks, while continuing to minimise your local validation error in the usual way.
👀 What’s next?
We’ll be rolling out more challenges that use multi-metric evaluation; whether you're working on geospatial analysis, time-series forecasting, or multimodal fusion, you’ll see this approach in action on Zindi in the coming months.
We’re committed to challenges that deliver real-world value (not just scoreboard hype) and this is just another step in that journey. We hope you buy into the vision too - multi-metric evaluation means tougher challenges and more relevant skills for your next role.
💬 WDYT?
This is a big deal for us, and we’re excited. But what do you think? Tell us what you liked (or didn’t). Got ideas? Drop them in the comments.
i am having fun