Have you wondered how data about an object or area can be collected from a distance without any direct contact? You are not alone if you have.
I am Chigozie Nkwocha, having a background in biochemistry and bioengineering. I claimed my first — and I hope one of many — first-place wins in the GEOAI Challenge for Cropland Mapping in Dry Environments Challenge.
Follow along in my GitHub repo.
In geography, environmental science and urban planning, remote sensing has been applied to monitor physical events on the Earth’s surface, atmosphere and water bodies using satellites or sensors (aerial or ground-level). These technologies have helped us to track changes in land use over time, assess damage from natural disasters, and analyse climatic/weather patterns. In agriculture, remote sensing is applied to monitor crop health, soil moisture, and land cover to optimise farming practices. This challenge was a classical example of remote sensing’s application in agriculture.
As we all know, machine learning techniques have opened a new chapter in how computational methods can be used to predict outcomes. In this challenge, we were tasked with developing an accurate and cost-effective machine learning model to distinguish croplands and non-croplands. HThe focus areas weredry regions: Fergana in Uzbekistan and Orenburg in Russia. These arid and semi-arid regions are characterised by complex agricultural landscapes. For example, they have medium to low vegetation due to minimal precipitation and high evaporation rates, which cause groundwater scarcity and affect agriculture in those areas.
Approach
You may be asking: What datasets did I use? What features did I generate and what model(s) did I use? We will get into that in a second.
Datasets
Satellites and sensors pick up physical phenomena, and as I mentioned, dry regions have very complex climatic/weather patterns. Based on this, I used three different dataset types.
- Sentinels 1 and 2
- Climaticdata (temperature, precipitation, land surface temperature and evapotranspiration)
- Physical structure data (elevation and slope).
Engineered Features
The next step was to preprocess the data and generate relevant features. . These features included polarisation ratio, vegetative, water moisture, and bare-soil indicesfrom the Sentinel datasets as well as water stress index (WSI) from the evapotranspiration data. These features capture vegetation and water availability in these regions.
The next step was to aggregate them into summaries for each reference site in these regions. You may ask why. It is because these summaries were aimed to capture the following:
- Temporal dynamics such as growth cycles and seasonal changes.
- Spatial structure by considering proximity to other croplands and regional patterns.
- Rate of change and volatility to identify abrupt transitions and sustained trends.
- Environmental characteristics of these sites such as variability, volatility and extremes of these climate and vegetation indices, including the vegetation moisture stress and soil exposure of croplands located in semi-arid regions.
Belowa summary (with code snippets) of the engineered features and reasons why they were generated.
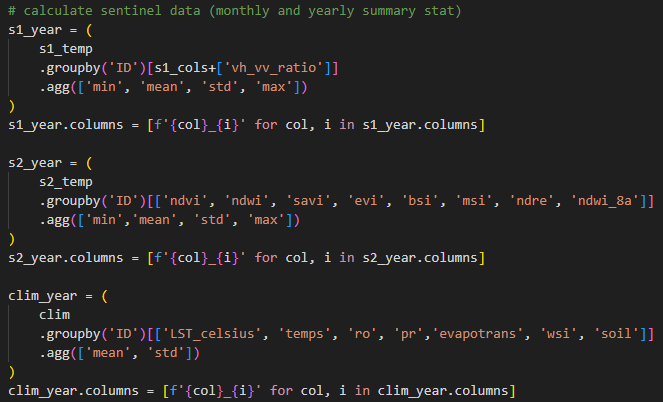
Annual Aggregates
These include min, max, mean, and standard deviation. They capture long-term trends and variability in vegetation indices, polarisation channels and climate variables. Croplands tend to show higher seasonal variability and distinct patterns compared to non-croplands due to planting activities.
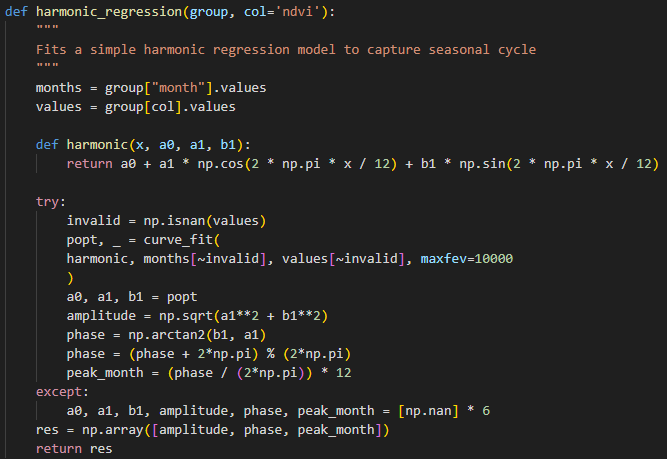
Phenology statistics
These include the peak time and magnitude of periodic patterns. They capture seasonal growth cycles of croplands and non-croplands as croplands tend to show predictable planting and harvesting cycles unlike in non-croplands, which often lack such pronounced cycles or different timing. A simple harmonic regression was fit to (code snippet)
Rate of change per month and acceleration
They quantify how quickly vegetation, bare soil, soil moisture or climate variables change over time and detect their abrupt transitions over time. Croplands undergo rapid changes during sowing and harvesting periods, while non-croplands tend not to have pronounced phenomena. A linear regression model was fit (code snippet)
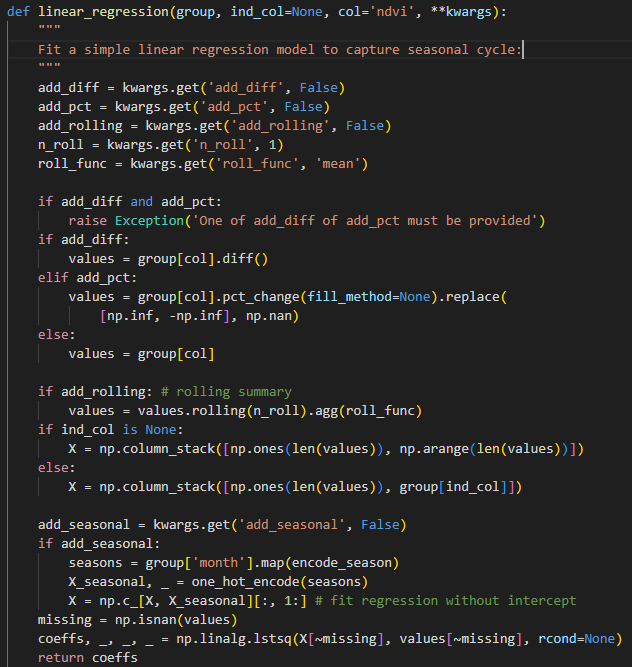
Rolling statistics
We calculated 6-month rolling sums, means or volatility (standard deviation). These smooth short-term fluctuations, capture medium-term trends and help identify sustained growth or decline phases, which are common in crop cycles but less so in non-croplands like pastures or steppes.
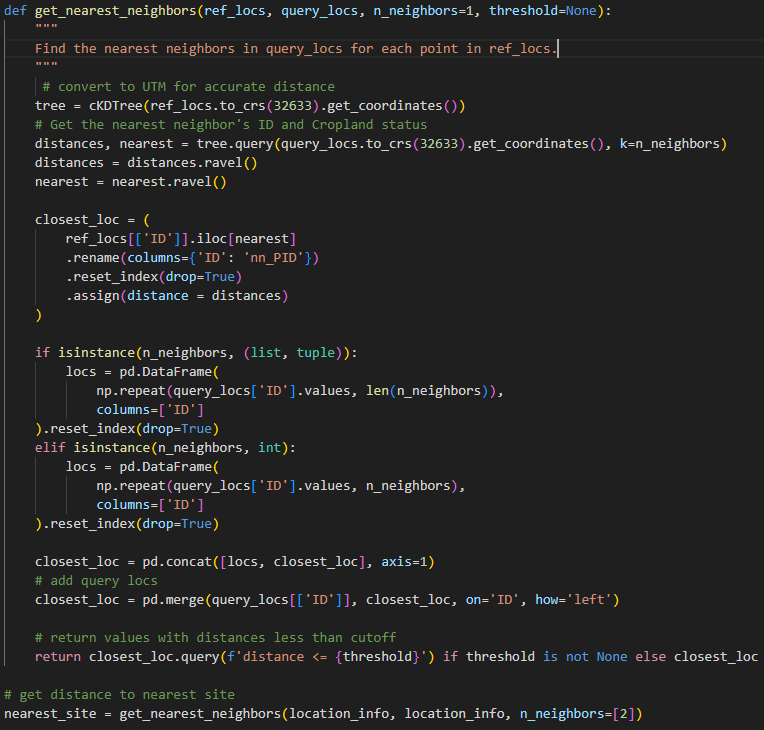
Distance-based features
These include the distance to the nearest site. Others are the average distance, dispersion of sites and the number of sites located within a 10km distance from a reference site. Croplands tend to cluster together, and the proximity to other croplands increases the likelihood of a site being used for agricultural purposes.
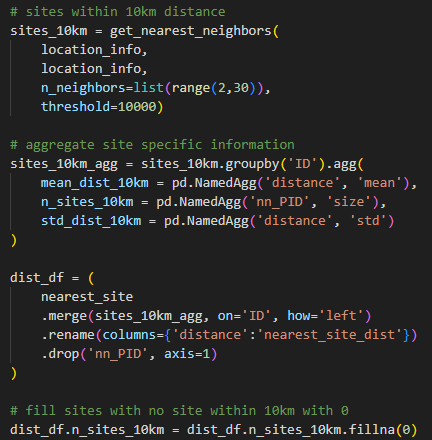
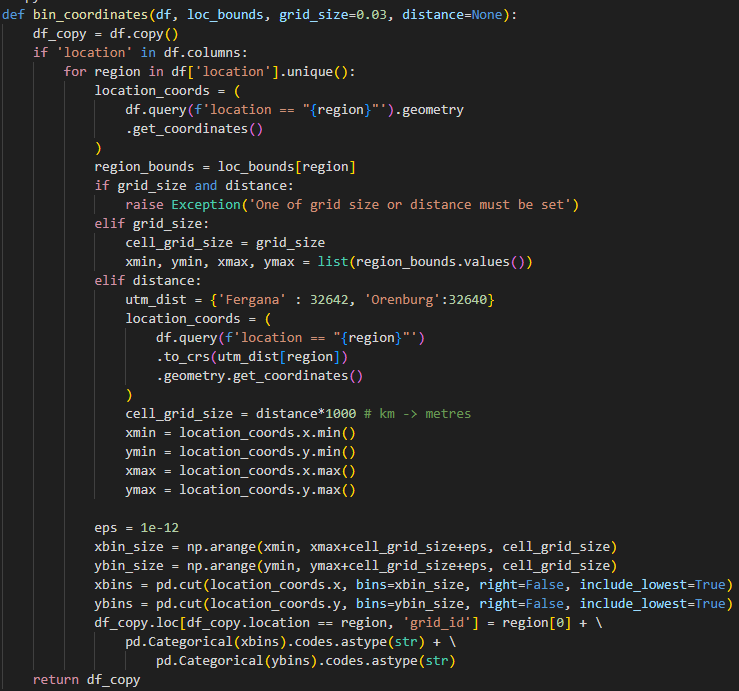
Grid-based aggregation
This captures regional vegetation or climate patterns of sites located within a region/area. The function below was used to bin coordinates into grids.
Clustering
Site coordinates for each region: Fergana and Orenburg were clustered into four groups (optimal number of clusters selected using the elbow method).
These engineered features were then saved and used for modelling.
Modelling and feature importance
With all features generated and saved, the next step was to develop a machine learning model to classify croplands and non-croplands. Three gradient boosting models: catboost, lightgbm and xgboost were used. Irrelevant features were dropped and one-hot encoding was applied to categorical features (region and cluster groups). The final model was obtained by averaging the probabilities of each model and assigning a cropland class to probabilities above 0.5 and non-cropland class, if otherwise.
You may wondering if I did not use a train-test split method to evaluate performance on held-out data before submitting to the leaderboard. Well, I did that at first, and was getting a good score. So, I decided to fit a final model on all the training data and then make predictions on the test data. From a 5-fold cross-validation approach, all three models achieved about 0.87+ accuracy, which mirrored the private leaderboard score of about 0.85.
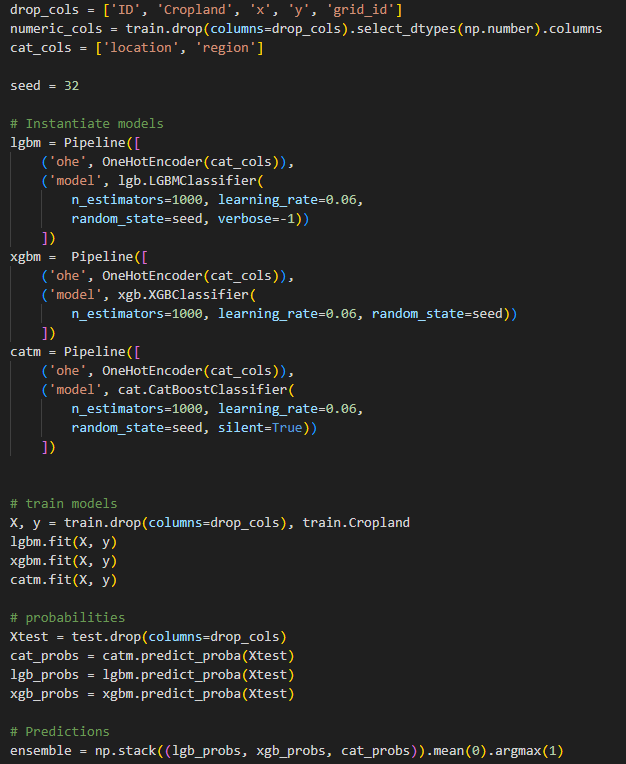
What are the important features?
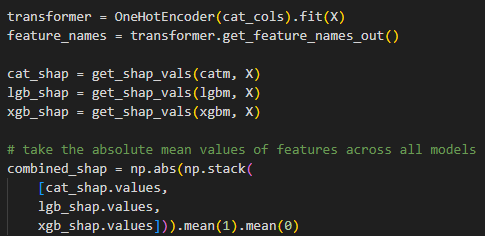
It doesn’t stop at developing a model; we need to understand the features that enabled these models to arrive at their predictions. To accomplish this, I computed and averaged the absolute shap values for each feature for each model. It was discovered that the top features for the three models were mostly from the sentinel datasets. These include the polarisation channels (VV and VH), vegetative indices, bare soil indices (BSI) and moisture stress index (MSI). These features are characteristic of arid and semi-arid regions.
To get a consensus score for features in the three models, we averaged these shap values. Here, we see that the peak time, represented by phase, annual minimum or maximum values, and annual deviations, the magnitude of their periodic patterns, represented by the amplitude, are some features that distinguish croplands from non-croplands. Others include their rate of change (or percentage change) per month, the rate of change of monthly changes (known as the acceleration), the variability of these changes (standard deviation), the slope of the site, and the distance to the closest site.
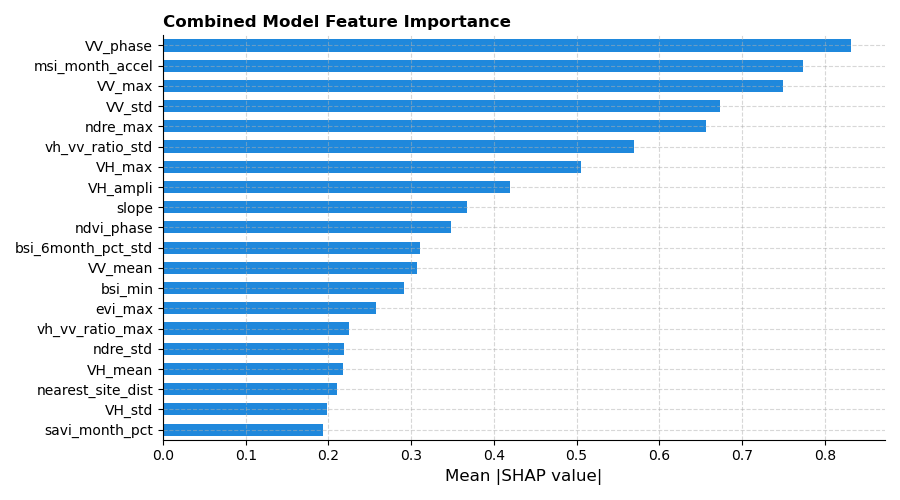
Figure 1: Combined Feature Importance
Final Thoughts
From this challenge, we learned how machine learning can accurately distinguish croplands and non-croplands using remote sensing data. We also saw that generating rich and relevant features related to the climatic patterns, physical characteristics of the region of interest, as well as their spatial information, are important for classifying cropland and non-croplands. Similarly, this solution offers a cheap and efficient method that can be adapted to other regions without the need for physical site visits.
For more on the datasets and Python scripts, here is a link to the repository.
About Me

I am Chigozie Nkwocha, with backgrounds in biochemistry and bioengineering. I am a data scientist and would-be machine learning engineer with a passion for developing practical solutions to real-world problems. With strong skills in R, SQL and Python, I have applied data science and machine learning techniques in health, biology, environment, and business. I specialise mostly in tabular data but am gradually transitioning into unstructured datasets.
I have participated in many competitions here on Zindi, and still participating. Participating here on Zindi has helped me gain experience in various fields and has honed (and still honing) my skill sets.