When working on a machine learning project, choosing the right error or evaluation metric is critical. This is a measure of how well your model performs at the task you built it for, and choosing the correct metric for the model is a critical task for any machine learning engineer or data scientist. The F1 score is a metric commonly used for imbalance classification problems.
For Zindi competitions, we choose the evaluation metric for each competition based on what we want the model to achieve. Understanding each metric and the type of model you use each for is one of the first steps towards mastery of machine learning techniques.
Before understanding the F1 score, it's essential to grasp precision and recall, the two fundamental components that contribute to it:
Precision: Precision measures the proportion of correctly predicted positive instances (true positives) out of all instances classified as positive by the model (true positives + false positives). It gauges the model's ability to avoid false positives.
Recall: Recall, also known as sensitivity or true positive rate, measures the proportion of correctly predicted positive instances (true positives) out of all actual positive instances (true positives + false negatives). It indicates the model's ability to capture all positive instances.

The F1 score is particularly valuable in machine learning projects when dealing with imbalanced datasets: In scenarios where one class significantly outnumbers the other, accuracy alone might be misleading. The F1 score provides a better representation of a model's effectiveness by considering both precision and recall, which are crucial in imbalanced situations.
In certain applications, precision and recall are equally important. For instance, in medical diagnosis, both correctly identifying positive cases (recall) and minimizing false alarms (precision) are vital. The F1 score allows practitioners to strike a balance between these two metrics.
The F1 score is best suited for binary classification problems.
This will help solidify your understanding of the F1 score, create a confusion matrix like the below and manually calculate the precision, recall and F1 score.
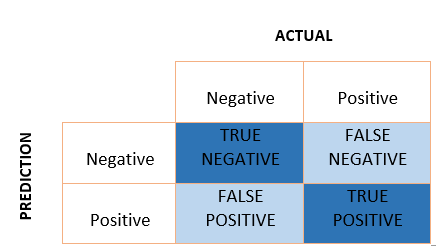
With this knowledge, you should be well equipped to use the F1 score in your next machine learning project.
Why don’t you test out your new knowledge on one of our competitions that uses F1 as its evaluation metric? We suggest the Xente Fraud Detection Challenge.
cool !
In the case of multi-class classification, which F1-score is used ? macro-F1 or weighted-F1 ? Thanks.