
Amini Soil Prediction Challenge

If you look at the data outputs in the starter notebook, the test rows are entirely different from the ones we were given. For example, these are the first rows that the sample submission model was predicting:
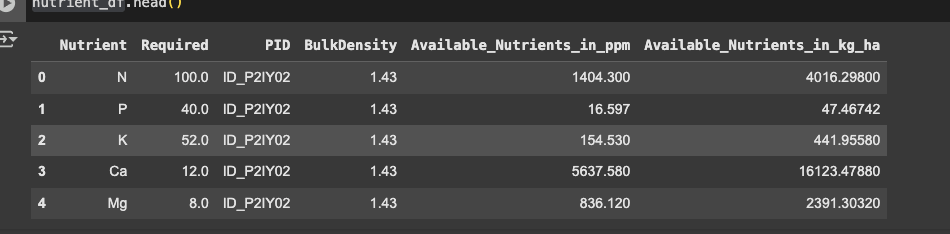
However, these are the rows (allegedly the same rows) that we are supposed to be predicting:
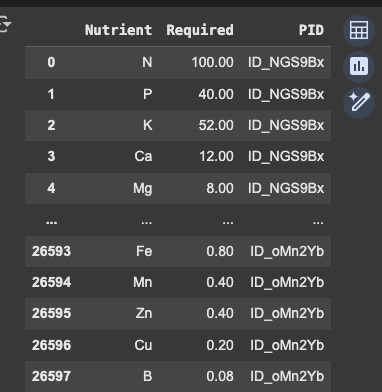
Clearly, the PID is completely different between the two. The PIDs used in the starter notebook do not even appear anywhere in the test set we were given. Not only that, but the BulkDensity values are entirely different (so it's not just the case that there are different PID labels, the two sets are legitimately different):
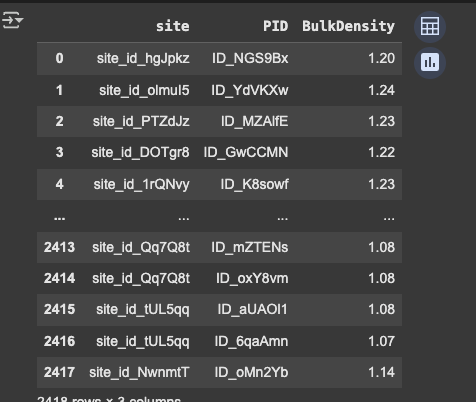
This makes me wonder if the hidden test set has the wrong data associated with it (i.e. it does not match the data we were given). If so, this would explain there is no correlation between CV and the leaderboard... the leaderboard is just not matching the test data we were given.
Could someone from Zindi explain this discrepancy and why the test BulkDensity values are different between the starter notebook and the test set we were given?
It's the same test set. It wouldn't make sense to have a different test set. You will get invalid submissions in your submission page if that was the case.
Not if someone accidentally mislabed the hidden test set, which seems possible given that there is clearly a second test set which you can see in the starter notebook...
I also think there is a difference between both test set because I have been trying to make a submission with the normal test set and it keeps saying I have missing entries even after thoroughly checking to see if I had dropped any row