
CGIAR Eyes on the Ground Challenge

Training and inference source code: https://github.com/quanvuhust/cgiar-eyes-on-the-ground-challenge
SPLIT DATA
I split train data to 5 fold using group kfold. Group by prefix in image name.
REGRESION WITH BCE LOSS
Follow kaggle competition petfinder-pawpularity-score, I train model classification convnextv2_large with BCE loss, label = extent/100. I train only one fold 0 because training time is limited in 8h. It is risk when using only one fold, ensemble of 5 fold can boost private score.
SOFT LABEL
I use soft label because some images have wrong label.
After train model with BCE loss, I gen soft label with ratio: 0.7*gt + 0.3*predict
Final submission is ensemble by 3 model of fold 0, PB 9.4 and Private 10.598.
+ convnextv2_large orignal label, fold 0 epoch 6, image size 384
+ convnextv2_large soft label, image size 384
+ convnextv2_large soft label, image size 448
EXPERIMENTS
- ensemble two fold, fold 0 + fold 1, soft label, multiscale

- I have experiment with caformer_b36_384_in21ft1k, dinov2 vit base, dinov2 vit large, swinv2_large_window12to24_192to384.ms_in22k_ft_in1k, convnextv2_large.fcmae_ft_in22k_in1k_384. It hard to achieve 8.x public without using dataleak. Ensemble more model boost score, however increase training time.
- I do some experiment to test leak data:
+ coat_lite_medium_384.in1k with metadata, using damage column and growth_stage column as feature , concat metadata feature and image feature.. Public: 9.4 and Private 9.54 with coat lite medium :))

+ Train model classify 2 class with swin large using Test.csv as validation (achieve accuracy 92.5 on Test.csv). DR as class 1, Non DR as class 0. Set all test image has threshold < 0.5, 0.6, 0.7, 0.8, 0.9 to extent =0, ensemble with regression result. Small improve from public 9.58 -> 9.55
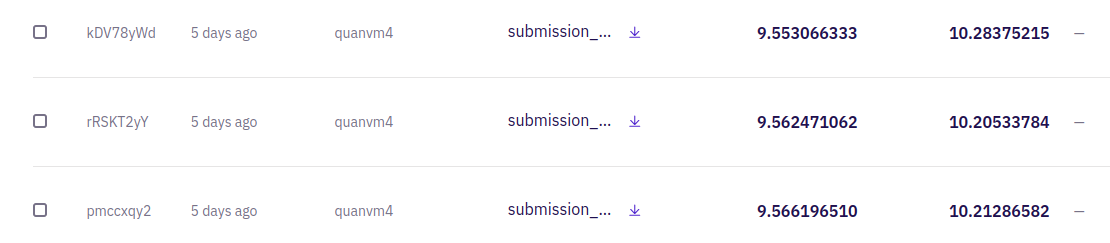
+ Compare result when training with all data and result using data leak (6.x public): RMSE between two predict (non DR test image) is ~ 7. Some test image has ground truth extent = 0, however model predict extent ~ 30, 40, 50, 60. I have visualized those images, they have wrong label. Some people can re assign value of model predict on such image to zeros (predicted extent = 0), this can boost RMSE score :))
Congrats @quanvm4. Nice pipeline !! It seems like Soft Label was the winner here.
Congratulations! I haven't heard about BCE loss approach for a regression, but it sounds really sensible.
But I'm not sure how you manage to train these 3 models in 8 hours, especially using 448 resolution. Did you use P100 for training or different GPU?
As your final models have the same architecture, ex. for 448 did you fine tuned 384 version or start from dino/clip checkpoint?
Soft label finetune from checkpoint epoch 11. I inference 448 size with checkpoint epoch 6 train with image size 384. I only train 1 model with fold 0 image size 384, finetune softlabel 3 epoch from this.
I using trick train with small resolution and inference with larger resolution.
From paper Fixing the train-test resolution discrepancy, https://arxiv.org/abs/1906.06423
Thanks for your answer. Now it is clear to me!