
DigiCow Farmer Training Adoption Challenge
'/%3e%3c/defs%3e%3cpath fill='%23fff' d='M-120-80h240V80h-240z'/%3e%3cpath d='M-120-80h240v48h-240z'/%3e%3cpath fill='%23060' d='M-120 32h240v48h-240z'/%3e%3cg id='b'%3e%3cuse xlink:href='%23a' stroke='%23000'/%3e%3cuse xlink:href='%23a' fill='%23fff'/%3e%3c/g%3e%3cuse xlink:href='%23b' transform='scale(-1 1)'/%3e%3cpath fill='%23b00' d='M-120-24v48h101c3 8 13 24 19 24s16-16 19-24h101v-48H19C16-32 6-48 0-48s-16 16-19 24z'/%3e%3cpath id='c' d='M19 24c3-8 5-16 5-24s-2-16-5-24c-3 8-5 16-5 24s2 16 5 24'/%3e%3cuse xlink:href='%23c' transform='scale(-1 1)'/%3e%3cg fill='%23fff'%3e%3cellipse rx='4' ry='6'/%3e%3cpath id='d' d='M1 5.85s4 8 4 21-4 21-4 21z'/%3e%3cuse xlink:href='%23d' transform='scale(-1)'/%3e%3cuse xlink:href='%23d' transform='scale(-1 1)'/%3e%3cuse xlink:href='%23d' transform='scale(1 -1)'/%3e%3c/g%3e%3c/svg%3e)
Helping Kenya
€8 250 EUR
Completed (4 months ago)
Data analysis
Classification
901 joined
377 active
Start
Jan 28, 26
Close
Mar 01, 26
Reveal
Mar 02, 26

Duplicates
Data · 6 Feb 2026, 16:04 · 2
I noticed that there are duplicate records in both the training and test datasets. While duplicates in the training set are straightforward to handle by removing them, seeing duplicates in the test set is more surprising. These duplicates appear when the ID column is not included. Do these duplicates exist by design, or were they unintentionally introduced during data preparation?
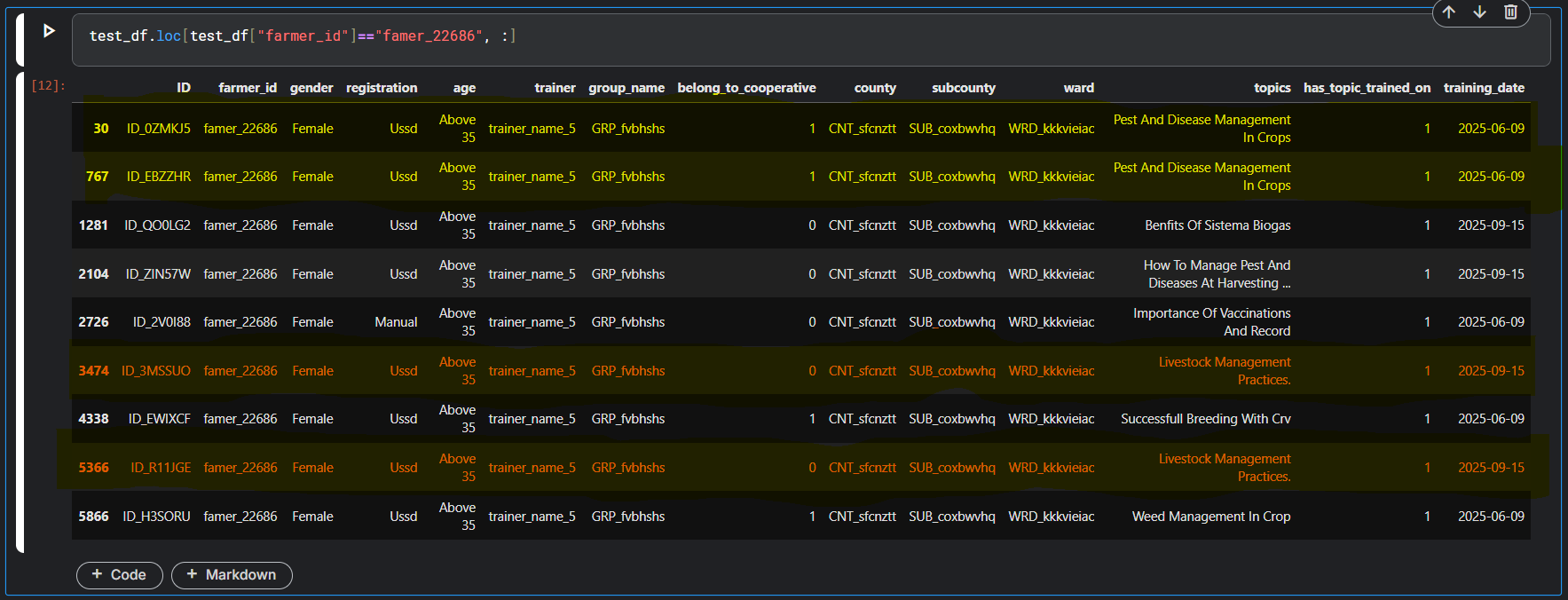
Data Conflict: Multiple records appear identical (differing only by ID) yet show contradictory adopted_within_07_days or adopted_within_90_days or adopted_within_120_days statuses.
Clarification: Does "adoption within x days" refer to specific topics trained on being adopted, rather than a one-time milestone triggered by the initial training session?
Yes that's a fantastic observation, and its true..... I did a time sensitive train validation split..... and I saw duplicates as follows : a) Train: 4054 / 7163 b) Val: 4098 / 6373 c) Test: 4322 / 5621