
Digital Green Crop Yield Estimate Challenge
'%3e%3ccircle r='20' fill='%23008'/%3e%3ccircle r='17.5' fill='%23fff'/%3e%3ccircle r='3.5' fill='%23008'/%3e%3cg id='d'%3e%3cg id='c'%3e%3cg id='b'%3e%3cg id='a' fill='%23008'%3e%3ccircle r='.875' transform='rotate(7.5 -8.75 133.5)'/%3e%3cpath d='M0 17.5.6 7 0 2l-.6 5L0 17.5z'/%3e%3c/g%3e%3cuse xlink:href='%23a' transform='rotate(15)'/%3e%3c/g%3e%3cuse xlink:href='%23b' transform='rotate(30)'/%3e%3c/g%3e%3cuse xlink:href='%23c' transform='rotate(60)'/%3e%3c/g%3e%3cuse xlink:href='%23d' transform='rotate(120)'/%3e%3cuse xlink:href='%23d' transform='rotate(-120)'/%3e%3c/g%3e%3c/svg%3e)
Helping India
€9 400 EUR
Completed (over 2 years ago)
Prediction
1370 joined
677 active
Start
Sep 04, 23
Close
Dec 03, 23
Reveal
Dec 03, 23

Digging Deeper: Investigating Potential Data Entry Errors
Data · 22 Nov 2023, 16:57 · 35
Hi everyone!
So, as the title suggests, I thought I'd share some of my thoughts about this competition so far.
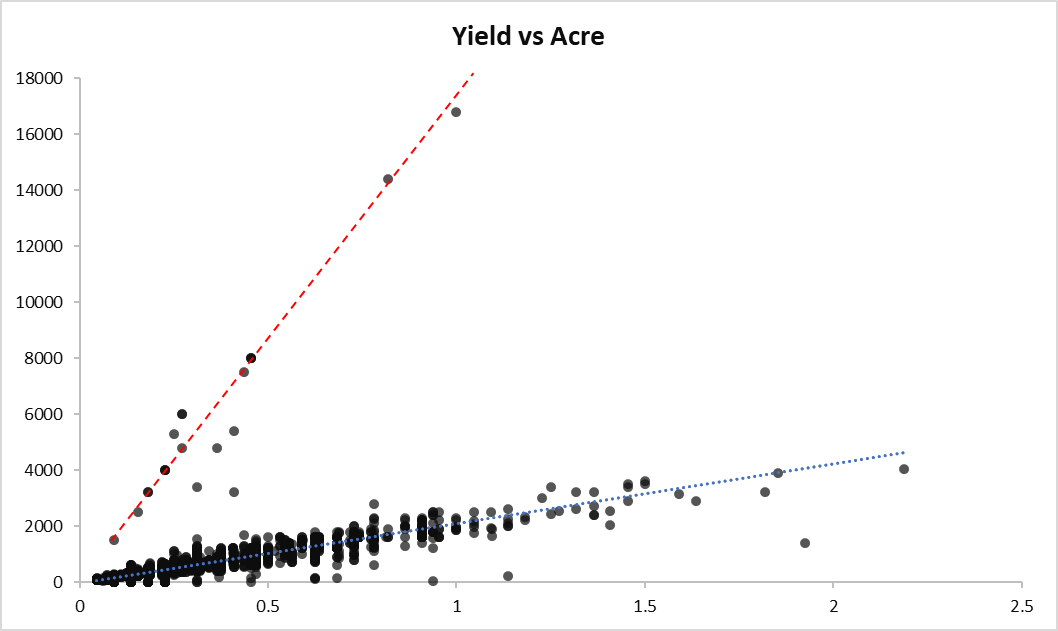
My theory is that these extreme yield values are not naturally occurring but are rather due to errors in data entry, where each value mistakenly received an extra zero at the end.
My suspicion is based on the following observations:
- All the outliers lie above the red line, which represents Yield*10 versus Acre.
- Dividing these outliers by 10 aligns them with the distribution of Yield, placing them back on the normal blue line.
- Quantitatively, these adjusted outliers show little difference from the other observations when divided by 10.
If this is true, the hosts might potentially overlook some high-quality models that could be created with the corrected data.
Assuming my suspicion is indeed valid, and should I offer my humble recommendation to the hosts, it would be advisable to thoroughly review the collected data.
I strongly agree with this point. Because of those extreme values in the target variable (that also seem to be present in the test subset), all those best-performing models and conclusions will be meaningless for the actual crop prediction. All this competition is about right now is outliers (errors) detection, which is certainly not usefull for farmers in India.
You're correct! Predicting outliers would only benefit the farmers if those extreme yield values truly exist. However, the evidence so far strongly suggests otherwise.
Let's be logical here – farmers generally have a good understanding of the expected yield range for each season. It's highly unlikely that a farmer anticipating, let's say, a yield of 1800 would suddenly end up with a yield 10 folds that amount.
This is precisely why I've dismissed the idea that outlier detection is the primary objective of this competition. Yet, it's the only way to "win".
I thought maybe the red line was the rice yields and the blue line was the wheat yields, but since they divide nicely by 10 back to the blue line, you're almost certainly right.
I also thought that there were at least two kinds of crops muddled into the data.
I also thought that farmers would know fairly accurately how much labour they would need to harvest a crop - yet there are substantial outliers related to the Harv-hand-rent column as well - possibly data entry errors.
Since you are currently in third position, I'm actually surprised that you shared such information. Like I mentioned in my post, luck will likely play a major role due to these unusual findings. While I agree with your findings, I must add that it's highly probable that the host is aware of the data inaccuracies. Let's be honest, if the misinformation wasn't present, there would be no need for a competition at all. A simple linear regression could suffice.
The information section states that the data was collected via survey. This method itself is prone to human error. Judging by how some features are presented in the dataset, I believe that the data we have has not undergone any preprocessing steps (apart from 'Acre'), so we are essentially dealing with the raw information collected.
This scenario is as realistic as it gets. In real-life projects, we often do not find clean data to work with. So, I think the intention of the host is: Can you build an optimal model that achieves a low RMSE while navigating through well-known misleading data?
Thanks for sharing your perspective. While I'm currently sitting in 3rd place, though that might not hold once the private leaderboard is revealed. Nevertheless, I think it's crucial to share such findings, especially if they could impact the competition's main goal: helping farmers predict their yields more accurately based on their practices.
I agree with everything you said until your last point on the host's intention: "Can you build an optimal model that achieves a low RMSE while navigating through well-known misleading data?" If we all agree these are inaccuracies or misleading data points, then why use RMSE, a metric that might encourage fitting to this misleading data? It seems like using any other metric would be a better choice.
I want to clarify that my intention is not to disrespect the hosts or those involved in collecting the data. It's simply to start a discussion that could ultimately benefit the core mission of the competition.
Fair points!
We do agree that these "outliers" did not occure naturally, as well as with point 1 and 2. Anyway, we disagree with point 3. You stated that there is little difference from the other observations - we do think that there are no differences and that some farmers just used a different unite in the yield column that can not predicted based on any other factors. Don't you agree?
A different unit is a perfectly valid assumption as well. I completely agree. However, that still falls under the category of a data entry or data collection error, which is understandable, especially when dealing with such a large number of farmers. My concern is more about the alignment between the competition's objective and the chosen evaluation metric.
I support your points. I'll add:
1. For the targets, there are cases that which the last 0 is missing (it's like divided by 10).
2. Not only the target column, such errors also happen for other columns like TransplantingIrrigationHours.
3. The target error also exists in the public test dataset. If you cannot get a better score on the public leaderboard, try to time 10 on the your prediction of 'ID_PMSOXFT4FYDW' to make it around 8000. I am pretty sure you will see significant improvement. That's the error in the public test.
To predict those errors in the private test, it's a lottery play for now.
Exactly.
Is anything going to be done about this? Surely producing a model that is overfit to entry errors isn't going to help farmers.
To me the obvious solution is to remove the data entry errors from the test sets.
I think it would different if the data entry errors were in the predictors. Those should be accounted for with our models. But it doesn't make any sense to keep prediction errors with the output variable, since there is very little value in being able to predict an error (we don't care about the error, we care about the actual yield!).
Nothing we can do here. Unless someone can explain and predict those errors, suppose there was a secret, they may keep quiet because that's the key to win the competition.
But for the hosts, they can either correct those errors or use other metrics.
The outliers' impact on RMSE is huge. You can try to do the math: suppose the target should be 800 and your model outputs similar value, but the wrong target is 8000 now, the single error will have 51840000 contribution. Although RMSE will take the average and then calculate the square root, for a dataset with 1000 targets, this error will boost the final score by about 200.
To be honest, I think there's zero chance that the metric will be changed. We are only 11 days away from the deadline, and several competitors have already submitted over 70 entries. I mean, we're deep into the hole... people have spent 3 months modeling with RMSE in mind.
Thanks Viradus for sharing,
I came to the same conclusion long ago and stopped competing.
My advice to everyone is to not waste your valuable time on such bad data with such bad metric.
Just make a good model without the outliers and hope for the best
Hi Viradus,
Is your best actual Lb score due to some lucky submissions or did you find a way to detect the outliers?
I wouldn't attribute it to luck. If you carefully examine both your training and test datasets, you can make an informed post-processing estimation. However, it's not guaranteed that it will translate accurately to the remaining 80% holdout set.
My assumption is that if the division between the public and private leaderboard test sets is stratified, there might be at least 3 or 4 additional outliers in the private test set.
Thanks
One thing is for sure: Guys with less than rmse: 130.0..... are lb probing. You can't get to those scores if you don't lb probe And I agree with you, the high yields in train are as a result of data entry, either intentional by the organizers or just by coincidence. If it was intentional by the organizers, what will happen to the solutiions that lb probe? to post process yields? Will they be disqualified due to these solutions not generalizing the outliers by themselves or what will happen? But if they were by coincidence then I don't think that post processing will lead to disqualification. Someone correct me if my take is wrong.
I agree that it's almost guaranteed that you won't come anywhere close to that score if you weren't doing any post-processing or error handling.
Regarding your last question, I don't believe there's anything against post-processing. In fact, you should almost always use post-processing if you have a good understanding of the distributions in your training and test datasets.
I think what Kolesh is saying is that in a real-world scenario, we would not have access to test data, so it would not be possible to use this kind of post-processing. Also, this kind of post-processing does not generalize.
I totally agree that for this case specifically it will not generalize.
But if you were referring to any other real-world scenario other than this specific competition, you can always create your own test set using resampling with stratification.
"I totally agree that for this case specifically it will not generalize."
That's the concern. If you have a high score because of this type of post-processing, it means that you only know the information because it was probed. And if it is information obtained through probing, it means that your model has zero utility. That's what I think Kolesh is aiming at here and I agree.
Yess , thank you @yanteixeira for simplifying my case
I believe we've already established that any model currently fitted for this competition will not serve its intended purpose 😅.
That leads us to an alternative question: Do you attempt to make your model predict outliers as well, or do you opt for post-processing instead? In this regard, I would argue that any post-processed model in this competition is preferable to any model that is being over-fitted to outliers (assuming these outliers are inconsequential). However, as you mentioned earlier, luck will still play a significant role in the end.
@VIRADUS what you are missing here is that Zindi has a specific rule for usability.
"Zindi is committed to providing solutions of value to our clients and partners. To this end, we reserve the right to disqualify your submission on the grounds of usability or value. This includes but is not limited to the use of data leaks or any other practices that we deem to compromise the inherent value of your solution."
That's why we are concerned about this kind of post-processing. According to the following rule, the model is useless, so it would not add any value to the host.
The main question here is: Will this rule actually be followed? Will Zindi check the code of the top 3 and disqualify those who obtained the information through probing?
according to this rule, all top ranked competitors will be disqualified?
It's time for the organisers to get involved and make things clear for us
@yanteixeira I'm sorry, how am I the one missing this?
I literally started this thread because I'm genuinely concerned about the practical impact of the models that will result from this competition for farmers. It feels like we're getting sidetracked from the main topic of our discussion. However, in response to your point, I'm willing to accept disqualification for my model. Nevertheless, I'd like to hear their reasoning behind the importance of accurately predicting these outliers organically.
Sorry if I chose the wrong words. English is not my main language, so I may have sounded rude. I don't want your model to be disqualified. We are on the same team here.
@mchahhou
In the end, you can choose up to two submissions, allowing top competitors to opt for a different model. You don't need to choose the model with the highest public score. However, I agree that Zindi should provide clarification.
Yes we are on the same team @VIRADUS @yanteixeira only that we want @ZINDI or the organizers to confirm so that we all know where our efforts will go these last few days. Huge respect to the top guys because even getting the other affected outlier id's in Test is a skill and not easy 👏👏👏
@yanteixeira @Koleshjr Thank you guys! Glad we're on the same side.
I hope this discussion yields (😉) something valuable. @ZINDI, I'm available to provide additional detailed evidence to support my belief that these outliers are incorrectly recorded as ten times the expected yield value, and how this hampers the intended usefulness for the farmers.
Thanks for this insights.It now make sense why my RMSE scores are not improving even after transformation
Hello Zindi Team and fellow participants, @VIRADUS @yanteixeira @ZINDI
I've been closely following the discussion in this thread and would like to request some clarifications from the Zindi team, which I believe will be beneficial for all of us participants:
Thank you in advance for your attention and responses.
Hello Amy,
I understand that as competitors, we have the responsibility to decide how to handle outliers. However, the main issue here is different: there's a legitimate doubt whether the data in the competition's target column are errors. These data have not been treated in the test bases, which will be used to evaluate the models. The presence of these outliers in the test datasets, without prior treatment, raises an important question: are they errors or natural variations of the data? A clear example is the ID ID_PMSOXFT4FYDW.
Our biggest concern revolves around the competition's metric, the RSME, which is extremely sensitive to outliers. If the outliers in the target column are indeed dirty data, this could irreversibly distort the competition's results. Therefore, it would be beneficial for Zindi to clarify in a binary way whether there are errors in the Yield column or not (Yes or No).
If the answer is no, then the main goal of the competition would be to understand why these outliers exist, especially from the practical viewpoint of the problem with RSME. If the answer is yes, and there are errors in the untreated test base, I disagree with your view on the relevance of the test distribution for the sponsor. The most effective models (and most important to the sponsor) would not primarily aim to predict these outliers.
If it is confirmed that they are errors, the structure and validity of the competition would be compromised, making the current approach inappropriate. It is crucial to ensure that we are not discarding or altering data that are essential to understanding the real dynamics we are modeling.