
International Women's Day Challenge

Congratulations for all winners. It was fantastic challenge.
The Solution Steps:
Architecture Diagram & ETL Process :
Extract : Data is sourced from CSV files hosted on GitHub, including training data, test data, sample submissions, and variable definitions.
Transform : Involves preprocessing, handling missing values, feature engineering (including geospatial transformations using H3 hexagons, distance calculations, and encoding categorical variables
Load : Transformed data is temporarily stored in Pandas DataFrames and used directly for training machine learning models.
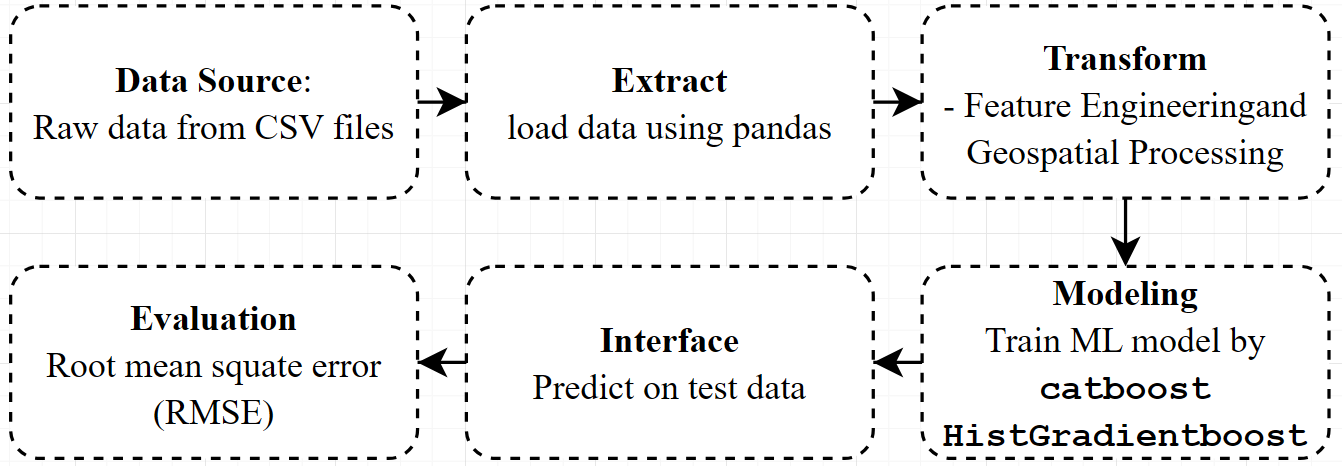
Data Modeling :
- Utilizes feature engineering techniques like geospatial processing with H3 hexagons and distance calculations.
- Multiple algorithms are applied, including CatBoost and HistGradientBoost.
- Model performance is evaluated using Root Mean Squared Error (RMSE).
Inference :
The trained model predicts outcomes on test data, outputting two columns, including the target variable.
Performance Metrics
Evaluation is based on RMSE, with KFold cross-validation ensuring reliability.
Public score: 3.47; Private score: 3.50.
for more details about the full solution please visit:
Thank you for sharing.
Welcome