
Lacuna Masakhane Parts of Speech Classification Challenge
Helping Africa
$7 000 USD
Completed (almost 3 years ago)
Classification
Natural Language Processing
470 joined
100 active
Start
Jun 08, 23
Close
Sep 17, 23
Reveal
Sep 17, 23

2nd Place Solution
Notebooks · 18 Sep 2023, 14:24 · 9
First of all, I want to thank the hosts and Zindi for this awesome challenge! And congrats to all winners!
Pipeline
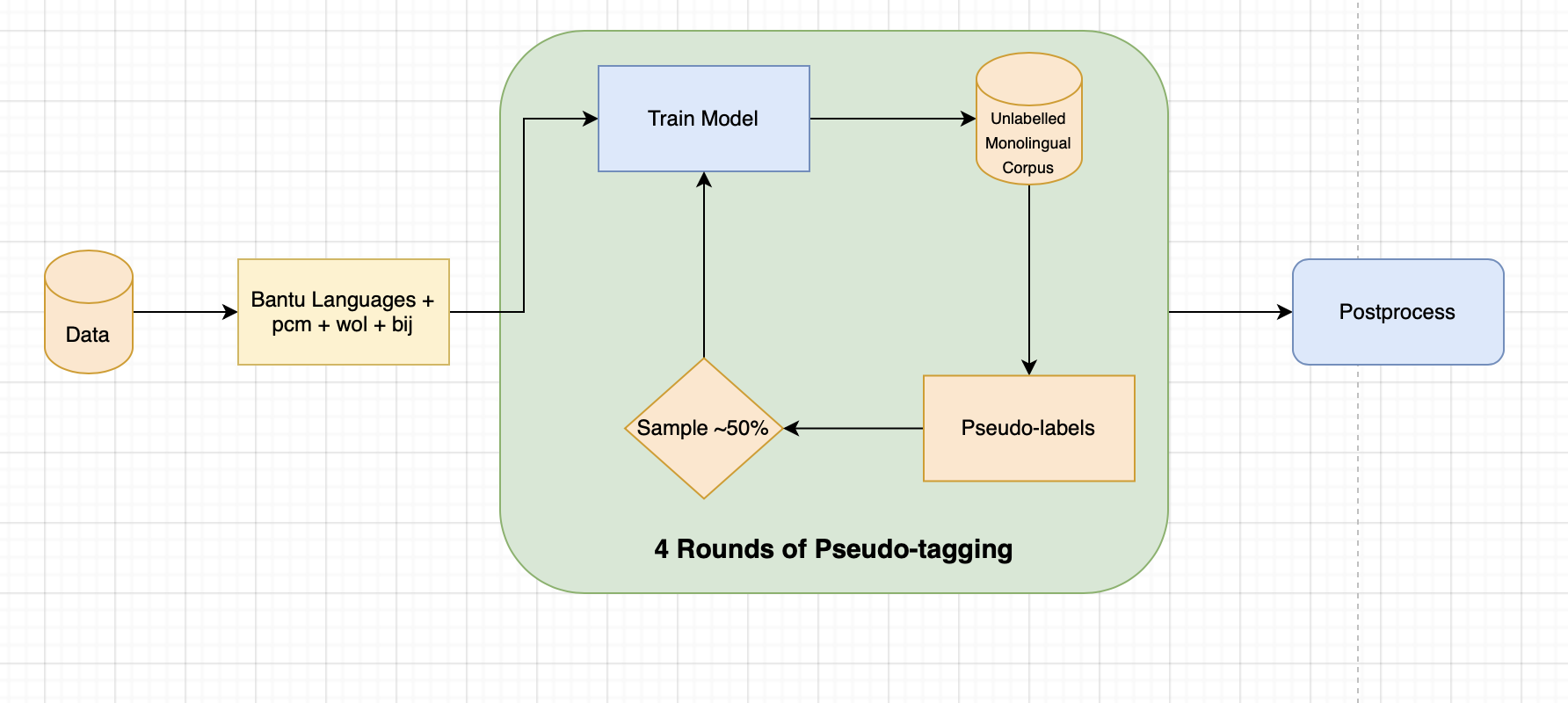
Validation Strategy:
GroupKFold on language columns: always leave two unseen languages during training for validation to mimic testset.
Model:
Afro-XLM-Roberta-Large + Custom Residual-LSTM Head.
Data Augmentations:
Data augs is a crucial part in my pipeline in order to push the model to learn multi-lingual features.
- CutMix:

- Randomly masking Tokens
Postprocessing:
Apply Nelder-Mead Simplex algorithm to optimize threshold for each class on OOF.
Nice. How much VRAM did you need to load the large model? I tried on 16GB and it didn't load, so I stuck to the base model.
I used a 16GB RTX A4000, and i train with mixed precision.
Congrats @Reacher on this, since it's a bit difficult task
Nice ! We also used refined pseudos but I think post processing and keeping too many langauges made the difference. Congrats on the top spot !
Congrats @Reacher. Just a question, could someone get >0.70 with normal Kaggle GPUS or Collab? P100s to be specific, if yes how? This goes to everyone who had >=0.70
Yes, training 5 folds do not exceeds 2.5 hours so i think on a P100 it won't exceed 3-3.5 hours.
Thank you for the writeup and Congratulations 🎉👏
Congratulations to you and thank you for the write-up. I hope we'll get a chance to see your solution code.
Congrats and nice solution overview !!!