
Lacuna Masakhane Parts of Speech Classification Challenge
Helping Africa
$7 000 USD
Completed (almost 3 years ago)
Classification
Natural Language Processing
470 joined
100 active
Start
Jun 08, 23
Close
Sep 17, 23
Reveal
Sep 17, 23

8th Place Solution
Notebooks · 20 Sep 2023, 22:52 · 5
I'd like to start by thanking @JEANMPIA on his contributions in the discussions. I can't recall how many times I said I was done with this contest :) I started working on it, 2 weeks before the end, and got stuck at 0.45/0.47 for the most part of it. Reading the discussions kept me going and ultimately led to this result.
Overview
My solution is an Afro-xlmr-large model finetuned on the provided training data, some additionnal data ( afrikaans, arabic, french and english ) and the 2nd rounds of pseudo labels done on Luo & Setswana monolingual data.
Pipeline
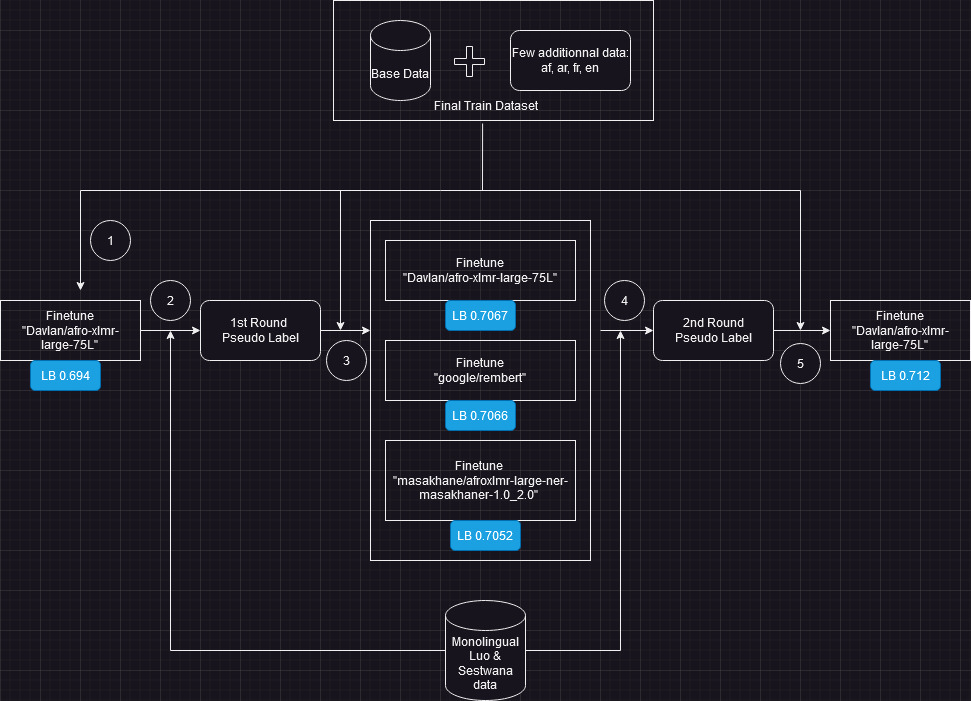
You can find the code here on github.
Great solution, It really seems like refined pseudos were key in this comp.
thanks for sharing
Yeah, seeing the gain, I wish I could have done a few more rounds :)
After the 4rth iteration, the boost is very small, but yeah maybe a few more.. :)
Congratulations and thank you for sharing
Good job Tuo 👏🏿 and thank you for sharing your solution 👍