
TAHMO Incoming Solar Radiation Prediction Challenge

Is it actually possible to achieve an MBE below 1 without using multiple accounts?
I ask because the answer is, quite simply, no.
Public leaderboard inevitably contain some degree of misalignment with respect to the underlying dataset. Lowering the MBE, starting from a model with a good RMSE, requires manually calibrating certain stations through post-processing based on the public leaderboard. This can be done to some extent, but how much can really be achieved with only 100 submissions available?
Can this kind of score genuinely be reached with a probabilistic model? Or is it the case that everyone with an MBE below 1, or with a leaderboard score above 0.6, has actually used multiple accounts and managed to cheat more effectively than others without getting banned?
I will let you reason on this and on the sens of this competition. It is frustrating starting an hard work and realising at a cetrain point that it is mandatory to cheat beacuse virtually all the accounts over you in leaderboard are doing it - ofc nobody is going to admit it, but I know you know it.
Think people, think.
PS1: just to let all of you remember who has not been banned
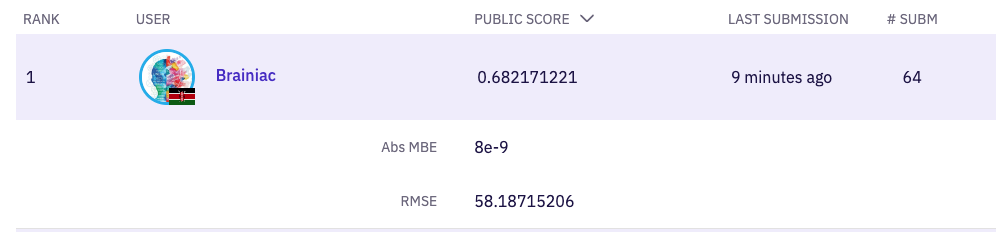
PS2: Oh, I am the still among you <3
@Uiziwi Your premise isn't really holding up, and honestly it reads like it's coming from not enough experimentation rather than the math actually being against you.
A handful of submissions is genuinely all you need once your CV is doing the work. You sanity check the direction of the bias correction, confirm CV and LB are moving together, and you're done. That's it. And look at the board, plenty of people are already sitting comfortably under 1, so the "it's impossible" framing isn't really matching what's actually happening.
You're being insencere here. You reached an almost perfect, 0 MBE at some point. If you are willing to be honest and say "I probed the leaderboard with 40+ submissions", I wouldn't judge you.. No multi-accounting needed for that.
But estimating each station's test-set biases from out-of-fold residuals is bullshit (getting 0 error for each station.. come on). As someone who probed the LB, I can confirm thay roughly half the stations have flipped signs compared to out-of-fold estimates.
Here's another interesting point: even probing won't get you to a perfect 0 MBE score. Not enough numerical precision in the Zindi score feedback to be able to nail it down to 8e-9 precision with only 40 submissions.
So yeah.. given that the accusation came from a cheating account.. they are right to flag you. You're not being honest.
Incorrect, my cheater friend @Brainiac
OOF residuals can help reduce MBE. Nobody is denying that. But they do not explain an MBE of 8e-9 on the public LB.
OOF estimates train-distribution station bias. The LB measures hidden test-distribution station bias. Those are not identical quantities. Random split or not, there is finite-sample noise, temporal mix noise, sensor noise, and refit noise.
So yes: getting MBE below 1 can be legitimate? You have to be "very lucky" without some external calibration. Getting it to numerical zero is a completely different claim.
Let's continue, because I am enjoying.
“Just use CV” is not an explanation. CV can give direction and scale. It cannot magically know the exact public station means to 8 decimal places. Also, saying “many people are under 1” proves nothing about how they got there. That is not evidence, it is leaderboard theology.
If this was really so easy, reproduce the 8e-9 MBE again with a fixed method, no extreme LB probing nor private label data leaking, and show the code.
Now the fake accounts are talking 😂 Mind you, this account was created 5 hours ago.
Reveal yourself, who are you?
and they are bragging about it - PS2: Oh, I am the still among you <3
At this point we can all guess who this is
LOL. It is clear
Dear multi-accounter.. you kinda ruined a lot of people's fun here, so I will optimistically assume you're just young and wanted to prove a point. If you managed to set up this elaborate multi-accounting vpn + registration+ submission pipeline (I really hope you were not insane and you didn't do it manually), you're clearly smart enough to do better things in life. What's done is done, get it out of your system, but do better next time.
It's a sybil attack, I'm glad I didn't invest that much into this comp unlike the frog challenge
Unfortunately, fgbfgb, you are not talking to that guy. And I totally agree with you, but unfortunately I am not the one at that level... Here the ocean is so big and what happened is very extreme. You are pursuing a wrong assumption: there is one single cheater...
OK, but just to remain educational: do you now get how ~41 submissions would have been enough to probe the LB? Not to 8e-9 precision, sure. But easily down to below 1 MBE.
I would say "maybe". Let me explain.
Assuming that you have not used tens of submisisons for testing and validating on LB:
- all the possible datasets and features engineering combinations
- many different families of models, as well as losses, metrics and OOF strategies
- the correct balance of MBE and RMSE on training data
- a strong anchor
- and so on with their permutation
then yes, with 41 submissions you can get close to 1 of MBE if you are skilled and luky enough to probe sing and magnitude of the offset of each station in one shot.
Shall this be true for all the people with MBE<1? Even for people with MBE close to 0.01? I don't know Rick...
You are overthinking this. Let's separate the MBE from RMSE. Say you make a submission with all zeros, you note down the MBE score. Then you pick station1, set all its row values to 1350, all other stations are 0. This gives you another MBE score.. from the difference of the two submissions you get back the exact station1 MBE. Then repeat for all other stations=> 41 submissions is all you need.
This doesn't say anything about RMSE, but it does recover the exact per-station anchors.
You could also use Hadamard matrices, but still 41 submissions needed.
And again, I don't think doing this is necessarily wrong or against the rules (I guess the organizers will decide that). But pretending no such method was applied by the top scores in the leaderboard would be a lie. And if their submissions history shows no traces of probing.. then that's multi-accounting
Hmmm....😊🤔
What worries me most is not even the cheating itself, but the normalization of leaderboard probing as if it were “machine learning skill.”
At some point, we need to be honest about the difference between:
If the primary path to a top score becomes extracting hidden station offsets from LB feedback, then we are no longer evaluating modeling ability in the traditional ML sense. We are evaluating who can exploit the evaluation protocol more efficiently.
In real industry or production environments, this mindset becomes extremely dangerous.
Why?
Because production systems do not give you access to hidden target statistics. Real-world deployments require:
A data scientist who overfits to leaderboard feedback is essentially training themselves to optimize for leakage instead of learning signal. That may work in a competition with weak evaluation protections, but it fails badly in production where future data distributions are unknown.
This is exactly why proper ML practice emphasizes:
The moment leaderboard probing becomes the dominant strategy, the competition shifts away from science and toward exploitation mechanics.
And honestly, that hurts everyone:
There is also a difference between:
Those are not the same thing.
The scary part is that some people start believing this is “normal ML.” It is not. In a proper ML pipeline, if your validation strategy cannot reproduce your leaderboard gains without adaptive probing, then your process is fundamentally fragile.
Competitions should reward:
Not who can turn the public LB into a side-channel oracle.
And beyond machine learning, there is also a life lesson here:
Not every win carries value, dignity, or prestige — especially when it comes through the back door. Not all money is valuable either, especially when it is dirty money.
Someone may see themselves as an achiever because of a ranking or prize, but outsiders often judge success differently. Real respect comes from integrity, skill, and fairness — not from exploiting loopholes while others are genuinely trying to learn and compete honestly.
That distinction matters.
Shalom !!!