
TechCabal Ewè Audio Translation Challenge
$1 000 USD
Completed (almost 2 years ago)
Classification
Automatic Speech Recognition
268 joined
80 active
Start
Aug 26, 24
Close
Sep 29, 24
Reveal
Oct 10, 24

Professor's Solution
Notebooks · 10 Oct 2024, 21:20 · 9
Hi guys, congratulations to all the participants, everyone is a winner!💪 this was an awesome challenge. I want to say a big thanks 🙌🙌 to Zindi, Umbaji and TechCabal. I had a great time hacking this one.
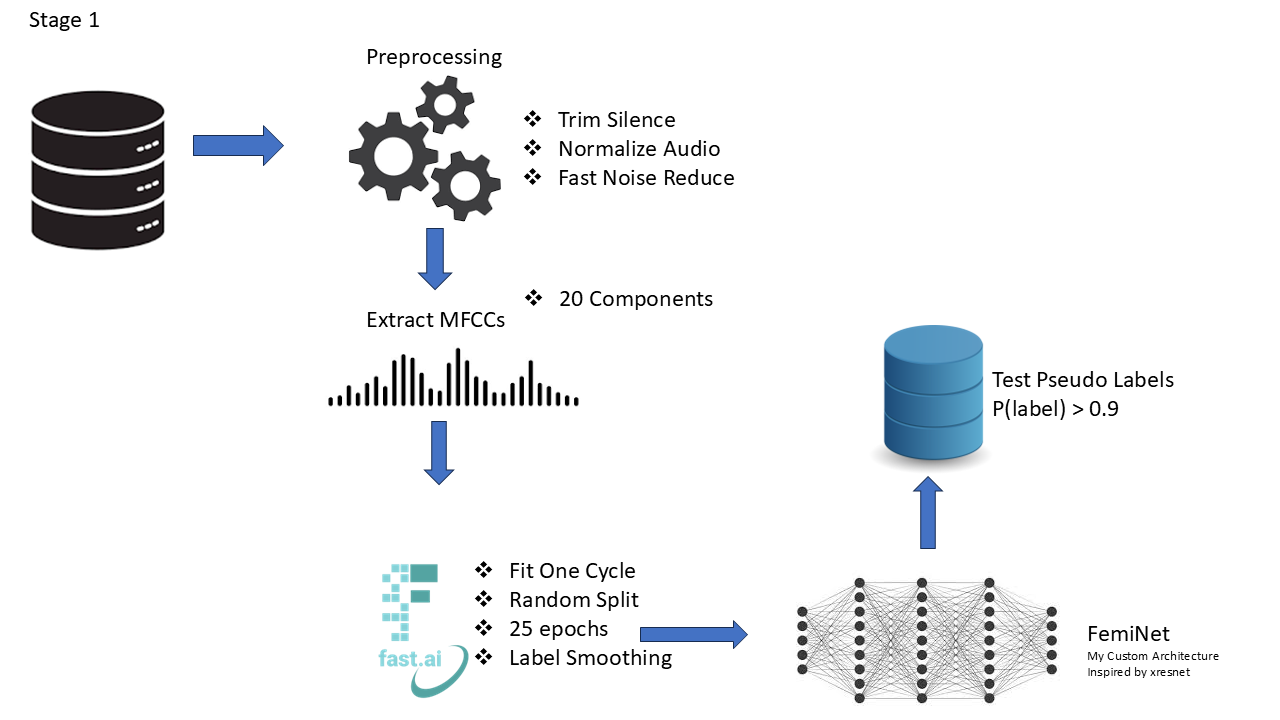
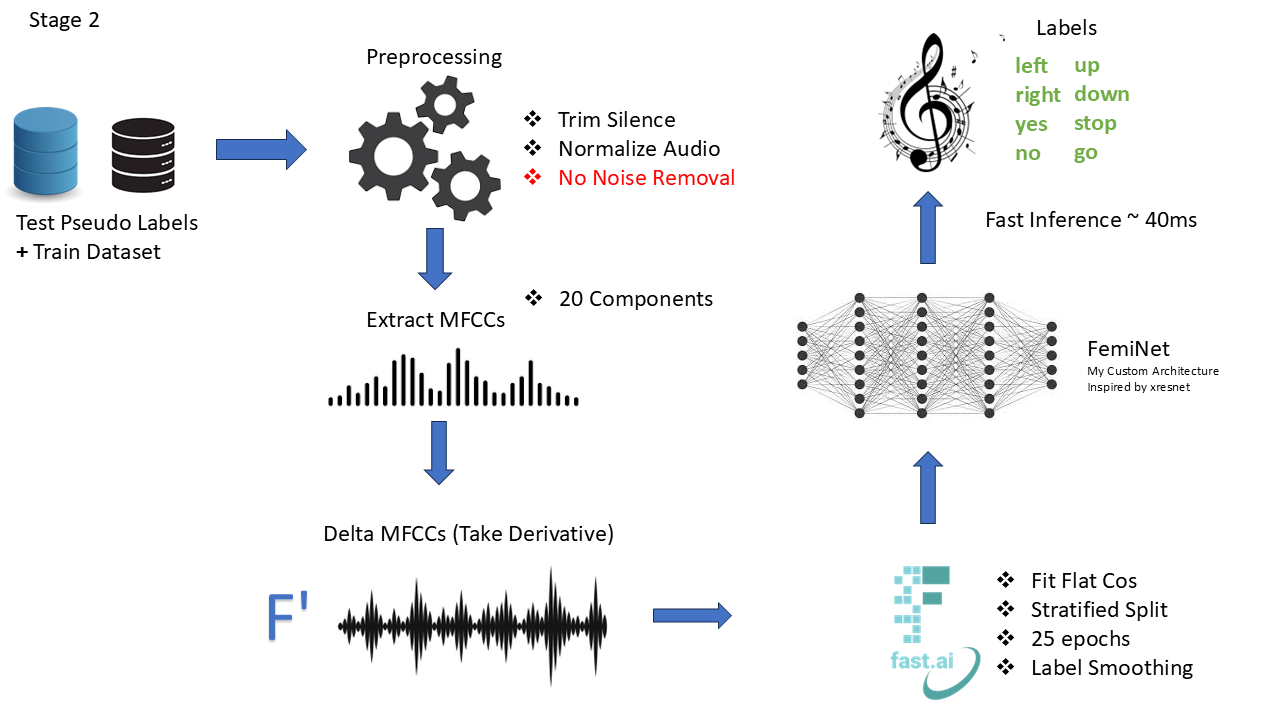
Folks, you can find my solution in this repo here. For folks that prefer kaggle notebooks, you'll find the two parts here(1) and here(2). I rewrote the solution as a tutorial to help beginners, but the overall idea is represented in the simple diagram below. Hats off to the winners ML_Wizzard and nymfree. You're geniuses! 👏
and ...............
congratulation and thank you for sharing
Amazing solution. I went with the basic sound event detection pipeline and applied an image model (resnet10t) to the extracted Mel spectrograms. Used time and frequency masking augmentation to help the model generalize better (LB=0.95 / PB=0.93). Slightly larger models performed better (PB = 0.95) but I didn't have the time to make model compression work on that one as its size was 18 MB.
what was the impact of noise removal on your local CV (or LB/PB)?
Noise removal was a gem. It boosted my CV drastically, unfortunately, it was too slow to meet up with the time constraints for the inference, so I switched to a faster method by reducing n_fft and hop_length, but it still didn't cut it. Eventually I had to find a way not to use it at all for the modelling hence the need for using pseudo labels and completely abandon the noise removal.
Thanks. It looks a very nice thing to have in one's toolbox. Will study your solution further
Congratulation prof.
Thanks boss
amazing solution. Quick question: how do you design your custom FemiNet ? . Why don't you choose a pre-defined neuralnets like MobileNet family ?
I used Moblienet-v3 in my final submission.
Hi @duongkstn, I simply just copied the xresnet architecture and made a smaller version (to control the size 10 mb limit). From experience, xresnets perform well in audio classification tasks. After getting close to 95% (public) on my first experiment, I didn't bother trying other architectures.