
Turtle Recall: Conservation Challenge
'/%3e%3c/defs%3e%3cpath fill='%23fff' d='M-120-80h240V80h-240z'/%3e%3cpath d='M-120-80h240v48h-240z'/%3e%3cpath fill='%23060' d='M-120 32h240v48h-240z'/%3e%3cg id='b'%3e%3cuse xlink:href='%23a' stroke='%23000'/%3e%3cuse xlink:href='%23a' fill='%23fff'/%3e%3c/g%3e%3cuse xlink:href='%23b' transform='scale(-1 1)'/%3e%3cpath fill='%23b00' d='M-120-24v48h101c3 8 13 24 19 24s16-16 19-24h101v-48H19C16-32 6-48 0-48s-16 16-19 24z'/%3e%3cpath id='c' d='M19 24c3-8 5-16 5-24s-2-16-5-24c-3 8-5 16-5 24s2 16 5 24'/%3e%3cuse xlink:href='%23c' transform='scale(-1 1)'/%3e%3cg fill='%23fff'%3e%3cellipse rx='4' ry='6'/%3e%3cpath id='d' d='M1 5.85s4 8 4 21-4 21-4 21z'/%3e%3cuse xlink:href='%23d' transform='scale(-1)'/%3e%3cuse xlink:href='%23d' transform='scale(-1 1)'/%3e%3cuse xlink:href='%23d' transform='scale(1 -1)'/%3e%3c/g%3e%3c/svg%3e)

We really enjoyed the competition and particularly spent a lot of time researching how state of the art facial recognition systems are built. We learnt a lot and continued trying ideas until the last minute. We would like to deeply appreciate @Zindi and Deepmind for organizing this great competition. Special appreciation to my teammate @ZFTurbo, it was fun working with you. Even with your Grandmaster status, you were down to earth.
Here is an overview of our solution, we hope you learn something from it.
Overview:
When I started this competition, I researched on state of the art facial recognition systems with several benchmarks- ArcFace, ArcFace Subcenter with Dynamic Margins, ElasticFace, CurricularFace, GroupFace, FaceNet and Siamese Networks. Every paper shows their own method is an improvement over the existing approach.
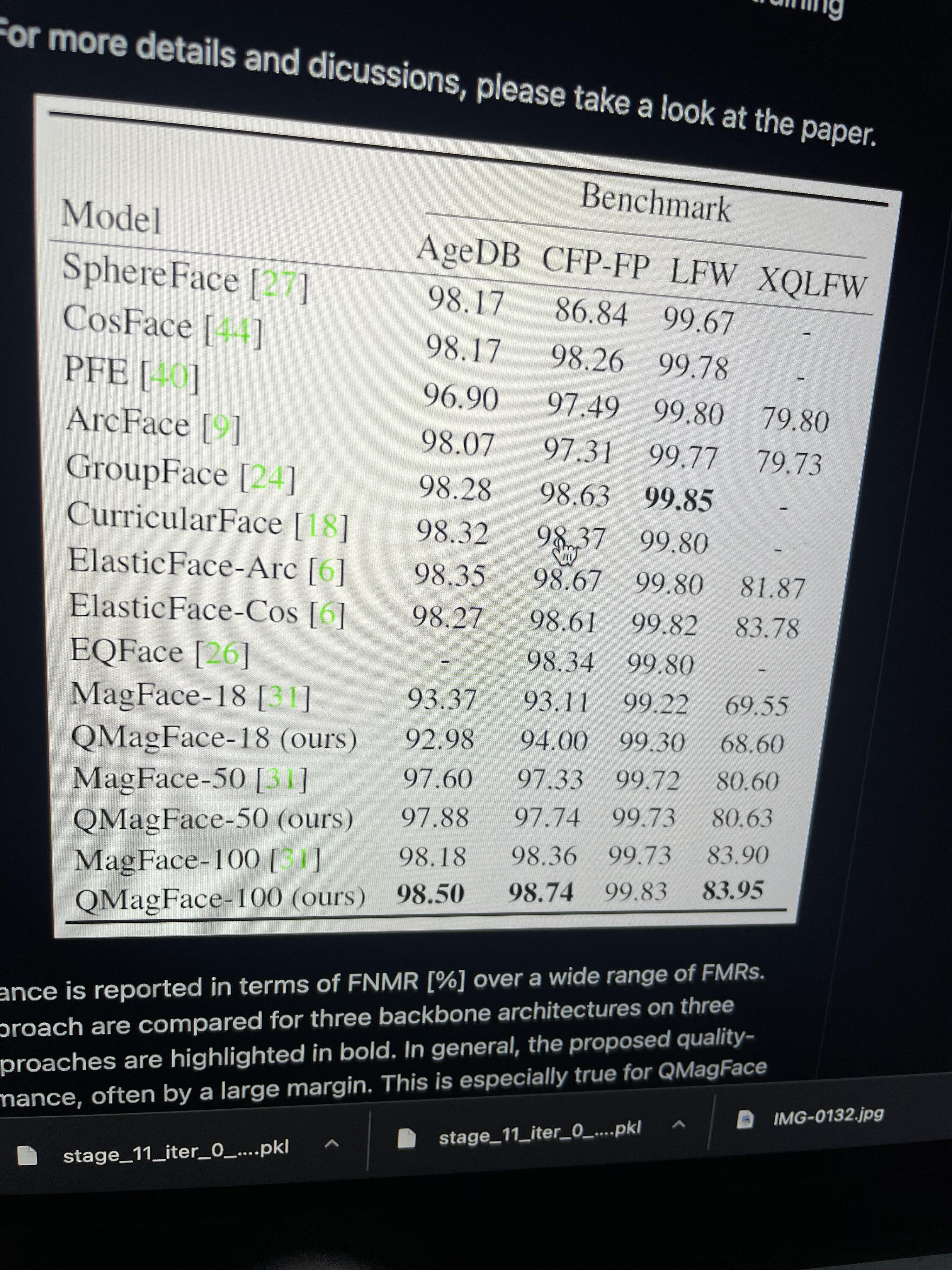
Most of the approaches will give a 0.9 on the leaderboard. After some testing with a validation set, ArcFace Subcenter with Dynamic Margins is the most effective, the general idea with dynamic margins is rather than using a constant margin in ArcFace, adjusting the margins due to the imbalance of the identities in the database helps convergence better-https://www.kaggle.com/competitions/landmark-recognition-2020/discussion/187757, https://www.kaggle.com/c/landmark-recognition-2021/discussion/277098
Dataset Usage:
Using ArcFace which is good for few-shot learning, we are able to utilize the full extent of the dataset to enforce the model to learn similarity for similar turtle IDs and dissimilarity for different turtle IDs. About 12803 images are used .
Augmentations:
Rather than utilizing image locations, we expose the image augmentations to similar image orientations in the dataset. This way the model can become location/orientation invariant. Even though the dataset has blurry images, using Blur augmentations had an adverse effect on validation. Hence, we stick to the following augmentations after testing on validation set performance:
HorizontalFlip(),
VerticalFlip(),
ShiftScaleRotate(),
CoarseDropout(),
RandomBrightness(),
Training/Validation Split:
Single Stratified Training/Validation Split due to time constraints-
Training: Turtle ids with < 3 samples are used only in Train data.
Validation: Turtles ids > 3 images.
We observed good improvement with the public LB for increase in MAP5 on the validation set, we checked other folds once and saw good stability with results. So, we stick to using a single validation set to select models and training routine for training on all data after model validation.
After finding the best epoch with an optimal MAP5 score, the submission routine for each model is trained using all of the data using the number of epochs with the best validation MAP5 score for the test time prediction phase.
Backbone:
Models: We used different neural net models for training and ensembling: NFNETs, ResNext, DenseNet, Resnet, EFF NETS
Training:
IMG SIZE – 420px
BATCH SIZE – 16
Optimizer - AdamW
Scheduler- OneCycleLR.
Embed Size- 512.
Optimal training settings for us differed for different models. All the models were trained with the public resources Google Colab and Kaggle GPU, training time for each model is about 6hrs. We train two versions of each model, one for validation comparison and other for test time predictions routine.
Validation:
Validation is designed in 4 phases to match the expected test time setup, we believe there are two kinds of new turtles- New turtles that will be from extra images that are not in the required 100 chosen turtles and new turtles that are entirely new, we have no images of them with IDs. Hence, we need a way to recognise these different turtles, recognising extra images of turtles is easier since we have data on them with IDs.
For each single model, using ArcFace we generate embeddings for each validation turtle, generate embeddings for each turtle in the training database. Hence a matrix of (Size of Validation images) x (Size of Images in Train Split). Using this split, we have a size of train 10269 and validation 2564.
First Phase- Using cosine similarity we pick the top-n unique turtle ids from the top-n images with highest cosine similarity in the database for each validation data. Best single model has a MAP5 score of 0.9489, last day's experiment increasing to 840px thanks to my teammate's infrastructure but no time to train all models, single model score can reach 0.953. This first phase of validation is to check the quality of the facial recognition detection for all images with turtle ids in the database (Size of turtle ID in database in 2265).
Second Phase- Concatenate model embeddings from each trained backbone for more diversity. Return cosine similarities for each validation image to the entire train database. Hence, a matrix of (Size of Validation image) x (Size of Train image).
MAP5 score from concatenated embeddings is 0.966.
Third Phase- Replace all the matches of extra images turtle ID not required of the 100 to be detected with the new turtle, also in validation set replace this IDs with new turtle. Return top-n images again. (Detecting new turtles that are in the extra images database but not required for the 100 turtle ids) .
Validation MAP5 score is 0.976. Since even though the correct turtle ID from extra images isn’t precisely detected, as long as it is an ID from extra images it still counts as a new turtle.
Fourth Phase- Detecting entirely new turtles not in any database, this is harder because we need to detect the unknown but after some research, it is seen that traditional facial recognition systems need to take this into account since a match will always be returned but the confidence score in the match matters. https://github.com/exadel-inc/CompreFace/blob/master/docs/Face-Recognition-Similarity-Threshold.md
We divide our validation set into folds of 3 and randomly change some turtle ids to new turtle, we remove this turtle ids completely from train data to match the representation of new turtle, we find best threshold with best MAP5 for top-1 prediction given that at validation time there will be turtle images with ids not in train. We further threshold prediction 2 to 5 with the same threshold, additionally since new turtle turtle had been detected in stage 3, we check to see if the cosine similarity at earlier position is less than threshold, if yes we instead shift the position of new turtle to that position. Each turtle id should only be detected once, we ensure this is the case. This works on the validation set, we find 0.55 to be best, which gives 0.9811 on validation set and about 0.9796 on public LB, 0.976 private LB.
Test Time Prediction and Submission:
Test time matches exactly the same routine as the validation setup.
Test Time Prediction- Initialize the corresponding model architectures from the Timm package for each model and load the trained model Checkpoint. Run through Train and Test data and output model embeddings for each individual trained model. Concatenate model embeddings for more diversity. Return cosine similarities for each test image to the entire train database. Hence, a matrix of (Size of Test image) x (Size of Train image).
Rank the train database matches: Replace all the matches of extra images turtle ID not required of the 100 to be detected with new turtle. Return the most unique top 5 turtle ids. (Detecting new turtles that are in the extra images database but not required for the 100 turtle ids)
Test Time Post-Processing- Detecting entirely new turtles using top-1 threshold, if max cosine similarity is less than threshold, add new turtle to the first instance of top matches.
Test Time Post-Processing(Second Phase)- Detecting entirely new turtles not predicted to be top-1 but possible to be top 2-5. Run through top-2 - top-5 if max cosine similarity is less than threshold, insert new turtle in position, whichever top spot is less than the new turtle threshold. New turtles should only appear once so an additional check is done to check if a new turtle already exists. Furthermore, new turtles could have been detected from the extra images being filtered as new turtle and could be in a later position, however if the cosine similarity at an earlier position is less than threshold, an additional routine rearranges new turtle to come in the earlier position. This is a check to confirm if the new turtle position needs to be shifted forward to an earlier position instead.
Due to model learning to be invariant, trying TTA to match the possible orientation in train database had no effect during validation testing. So, we drop TTA since that will prolong inference time trying several augmentations and doing a mean/max cosine similarity.
Other(Possible Ideas to reach 0.98 on Private LB):
- Train on larger image resolutions
- Pseudo-labelling this worked on private LB but only a small margin, no significant improvement on CV but with larger dataset, this can have effect. Since there are more images to be added to database for a match check. On validation set, for cosine similarity scores of 0.75, model is perfect without any errors.(So, we can add images with this confidence score from both test set and images in directory not in extra images or train).
- Combined face ensemble(Concatenate or weighted average with other face recognition, this improves validation score but too much model complexity for only a small boost)
- Ensemble with Siamese Networks, this improved private LB but by a small margin.
- Using SuperResolution algorithms to maybe improve blurry images, bit hard but might work
Acknowledgement
We deeply acknowledge great OSS such as PyTorch, PyTorch Lightning, PyTorch Image Models, Albumentations, etc.
I will be glad to answer any questions about the approach.
Beautiful solution. I'm amazed by the methodology and the progressive improvements.
Great job to you guys.
Very nice detailed writeup. Thanks
Thank you for the nice explanation, and a big congrats to you and your teammate, awesome work!
.
A lot of research and hard work here! well done @flamethrower, great solution!
@flamethrower Great job Damolar..... What a thorough research..... Well deserve guys. Bravooooooo...👍
Impressive! Great approach ! Congratulation, and well deserved. I also found that ArcFace Subcenter and cosine simmilarity were pretty effective.
amazing solution! can you also provide the implementation ?