
Zindi New User Engagement Prediction Challenge

Hello ZIndians, This was a tough competition and congrats to the top guys and congrats to everyone who took their time to engage in this competition.
This is going to be a long post haha.
I don't know if this is the final leaderboard scoring but if it is something is so wrong. So three days ago I got a very high score on the leaderboard at that time. The score was 0.6819 and I was shocked because it was very sudden. I had not done any new feature engineering or tuning whatsoever and I knew something was wrong. On further analysis I noticed that I had a sample submission file of shape 2050 which had some of the User_ID rows duplicated with the same Active target. After removing the duplicated rows and getting the shape similar to the Sample submission file provided (1340) and again submitted the submission, the score was 0.4484.
After seeing this unusuall boost in score based not on the model but on weird duplication of some rows in the sub file, I knew for sure this model won't stand a chance on the private leaderboard and so I decided to stick to improving my local cv and submit non duplicated rows as that is what will be important in real world scenario. You can't improve model perfomance in production by tweaking the sample submission shape haha. Other than that since I have been an active competitor, I referred to this discussion by mohammad eltayeb on Alvin and the follow up reply by flamethrower based on not using ungeneralizable aspects.
So yesterday when it came to choosing the two best scoring submissions it was easy for me not to choose the 0.6819 one because in real sense its score was only 0.4484 but somehow duplicating some of the rows gives such a huge boost? It does not even make sense why to be honest. I decided to stick with my two best models locally and pubic lb without the duplicated rows only to wake up and find that the "wrong" submission still stands with a score of 0.6819 and I thought maybe I never analyzed that code well and so I got back to it and did further experiments.
I then noticed that my earlier analysis was correct and that the high score was based on those rows duplicated, so on top of the 0.6819 I decided to do 3 more rounds of duplicating and these are the results.
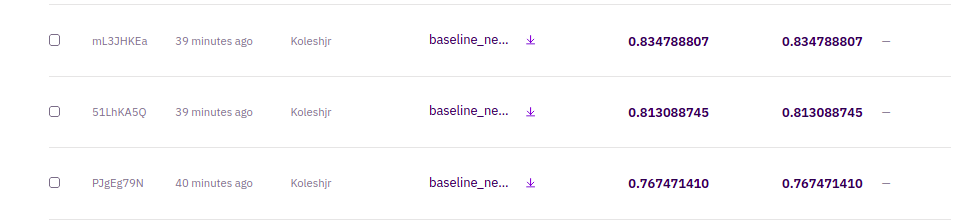
Shocking I know, so either the submission score scoring is wrong or this is not the final leaderboard. Removing all duplicates from the 0.8347 submission gives me a score of 0.4484 which is not as good

So you might ask how are this rows duplicated? It is as shown below. This represents the submission file with 0.8437.
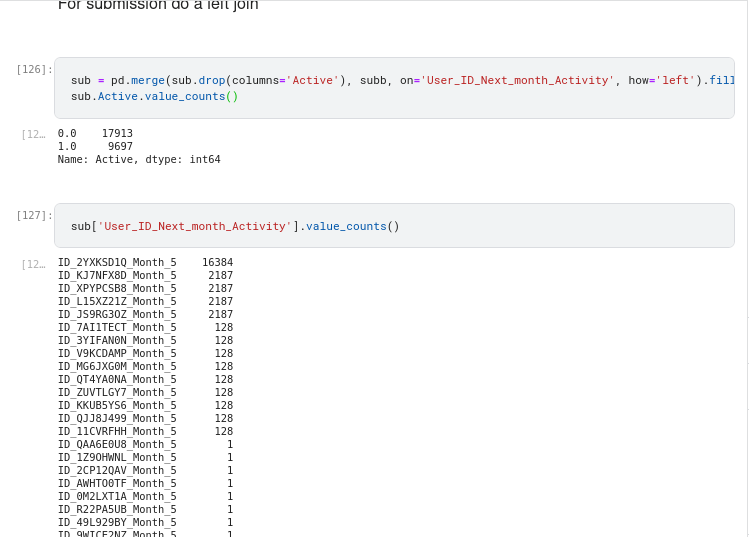
Let's contrast the shape before and after dropping the duplicates for the 0.8347 sub and the 0.4484

Clearly @ZINDI @amyflorida626 you can see that something is wrong, VERY WRONG. That was why it was easy for me not to choose this submission and choose only my best clean model's submission.
The dilemma of which submissions to choose continues. Should you choose the best model with the best cv locally or just a submission that scores highly on the leaderboard and you can't explain why?
Always trust your CV is my mantra for all competitions and I will continue to do so.
Gracias, Adios
What!
This needs to be looked at @ZINDI, @amyflorida626
I did not know the system could be tricked this much!
Thanks for disclosing this issue.
Additionally, I see that public and private scoreboard looks exactly same
Yeah, Looks like it has not been updated
Yes , hope the final leaderboard will be updated resolving all these issues.
Wow! Thank you for bringing this. @zindi should please review the submissions. I didn't even see this as I keep wondering how some participants were getting very high score🤦♀️
Thank you so much for your analysis and for sharing ! Hoping that @Zindi will look into this and update the private LB
True like even getting > 0.50 that's really great work if the sub is same Shape as the
Thanks for sharing this great analysis. I was suspicious when I saw the large scores incoming.
My one complaint (and I posted this early on) was that they should of shared the exact ID_months we were predicting for: It's silly not to know who you are predicting for and would have avoided this situtation.
Hoping @zindi re-run the LB with duplicates removed (unless the PB hasn't been run yet)?
The rules states that public leaderboard was just 30% . The private lb 70% . Matching public and private means the public lb was 100% maybe??? If not then maybe the private lb has not been run yet
Yeah this could be the issue.
Disappointed if there was an error - could have been easily fixed.
Im guessing the bug is easy to fix:
If you submit someone twice, they get included twice in the scoring. If you found ONE correct person you could probably just submit then a million times for you score to tend to 1.
When I get back to my laptop I will Try to do more rounds of duplicating and test this hypothesis
Yeah ! I said that to AMY last week and no reply ! I will mention u in the discussion
Hopefully we will get @ZINDI take on this
I sent them about the issue and they did not reply -which is fair-
The duplicates affect the f1 score if you are duplicating the true positives which is the case in this competition as the duplicates are the users with multiple records in all the datasets and those are generally active users.
@koleshjr however, you can not duplicate the users manually, you need to find a strategy to get a good number of duplicates for the users that are the most expected to be active.
in the end, the duplicates are more wrong than right.
Like Zindi always says, might the best model wins regardless of anything else.
"Like Zindi always says, might the best model wins regardless of anything else."
That would be a ridiculous result, the 'best' model (I appreciate yours) is cheating by simply duplicating IDs.
The LB is by no way a measure of how well a model will perform in production/reality, since you can't have the same person multiplied thousands of times.
But I really don't think that's what Zindi wants? For each user and each month you should have only one prediction right ? How does having multiple (same) targets for one user In each month help the business logic ?, the correct score should be calculated by removing the duplicates and you will have generalizable, true and realistic results in my opinion. But honestly my opinion doesn't matter, Zindi's opinion on this is what matters so let's wait for their take regarding this😁
If Zindi choose to not re-calculate the LB with duplicates removed I for one would be pretty annoyed.
@FC I said the duplicates are "more wrong than right" which we all agree on.
The last line is what they always say, I just quoted it, they will decide the best model according to their needs
I've confirmed you can get a score of 0.99 simply by copying one persons predictions 100,000 times! See; https://zindi.africa/competitions/zindi-new-user-engagement-prediction-challenge/discussions/15067
As for what makes sense and what does not, I can tell you that I got more than 0.92 f1 score on the validation set. a score that is impossible to get in the test set due to the covariate shift.
If you have analyzed the data you will notice a huge difference in the distribution between the training and the test set. Now usually you can fix this but for this competition case you can not (for example, the mean correlation between the training and the test set is about 0.03)
From all this, you can say that by simply adding more data to the training set, and with the right sampling, you can achieve very high scores in production using almost any model you can think of.
that is cheating, you can not duplicate users manually
I'm sorry - you are false.
I'm guessing your submission has duplicate IDs?
yes, you can not pass 0.5 without duplicates
Yes, its simply because Zindis leaderboard calculation code is errornous.
It simply checks if the user ID is expected and then calculates F1_score over ALL submitted rows - allowing for duplicates.
I'm hoping they remove duplicates before calculating the leaderboard.
Crazyyyyy nearly a perfect f1 score, surelllyyy this is not it 😅. This isn't even healthy competition
That is really impressive well done 👏
I think you may have the top scoring non-cheating submission!
Interesting that I have no duplicates and have 1383 IDs
If I had known this like you, I would have raised the issue before the end of the competition so that zindi could handle the issue quickly.
Now I think, it would be better to postpone the end of the competition so that people can compete again and come up with solutions without these issues
I raised it about 10 days before the end, another user @klai has done the same but they did not respond. Dealing with duplicates is an important decision for competitors to make!
This should just come naturally as a data scientist. That what you are building is actually going to be used in a real world setting, you are not getting paid to build cheating submissions you are paid to build robust models that actually have an impact when deployed. By this it shows that most guys actually did not understand the project objective in my opinion. But we can sit here all day arguing, but at the end of it all what matters is what Zindi will say about this so peace y'all✌️
@Koleshjr What do mean by cheating submissions ?
Do you think that had been done on purpose ?
If that was the case, why not go for 95% score or even more ?
Have you seen @FC discussion where he has 99% accuracy?
I sow that, but I am talking about "cheating submissions".
When you say cheating submission is like you are saying we did it on purpose, which wasn't the case for me otherwise I would have got more than what I have on the LB.
So, let's @zindi handle this issue in the best possible way for all of us
SOme people knew duplicate IDs boosted LB - as evidenced here.
I don't think they fully understood the implications though and were not being malicious.
Essentially, people with duplicate IDs are being rewarded (via higher LB score) for making mistakes in their prediction pipeline. I have faith that @zindi will fix the issue though, it is easy to fix simply de-duplicate as shown in my discussion.
I did not think of even trying this, since it is clearly a ridiculous way to boost your score.
Sorry data king for the wrong choice of words
Hi @koleshjr,
Thanks for making an open discussion about the issue. I was suprised to see people jump to 70 or 80. My thought was that they found the magic and was exploiting it. Never thought of gaming on duplicate rows.
Normally, I don't like to get involved in these kind of discussions. But I've been seeing these patterns for a few times now. And it is sad that @Zindi isn't more reactive about these issues. I was at least expecting a statement from them and also solve the issue since they knew it since last week. These kind of thing undermine both the competition and the platform.
True , I was also expecting them to address this issue the same day I raised it but turns out we have to wait longer. Hopefully we will get a response from them I hope. But this should not demotivate anyone from building strong solutions. Continue building better and robust models🙂
Yeah, you're right. Even though I joined quite late, I tried to build a good model, tried many approaches hoping to catch up a little bit with the top10. But seing how far I was (with people having 2 times my score), I thought I better use my time for something else. Knowing about the issue at that time would have been great. Maybe I would have kept working and improving my model. But well, may the best model wins 🏆 🤪
Same here . I joined in the last 5 days hoping to get a place in top10.But seeing people getting over 70 demotivated me . These kind of issues should've been dealt with quickly.
Yeah, exactly.
Well noted, thank you. Please do check we have authentic models as winners