
Difference Locations in Train and Test sets
Data · 16 Jun 2025, 21:04 · 7
Locations in the test set are outside the range of training locations; which might cause models that overly rely on lat, lon features or earth observations data to overfit to the training set.
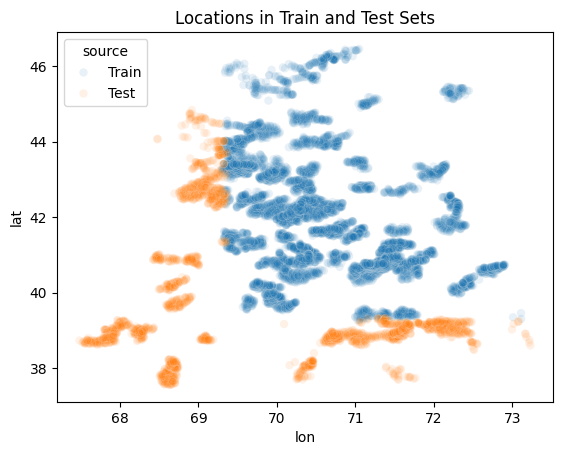
Update: After testing various models, location-dependent approaches consistently outperform others in both CV and LB scores. The best-performing model actively uses location data without overfitting, still note minding this difference between train and test data.
This is intentional and expected, You will vary rarely have competition with random sample, in addition the 30/70 Public/Private hold out sample split is not random also, that's why in most cases You will have significant shake up.
Interesting! In this case how do you avoid shake up?
I think random forest handles such noise better, however a shakeup is inevitable because of the RMSE metric.
What do you guys think? @omerym10 what models are you using?
Im using xgboost it gave me better score in cv and lb. But only after tuning hyper parameters.
Oh interesting. Mine is random forest. Funny enough xgboost gave me the worst result maybe because I didn't hyperparameter tune. I was around 14xx 😅.
Yes out of the box random forest gave me the best lb score but after tuning the best was xgboost.
That is great. Good luck!