When working on a machine learning project, choosing the right error or evaluation metric is critical. This is a measure of how well your model performs at the task you built it for, and choosing the correct metric for the model is a critical task for any machine learning engineer or data scientist. Word Error Rate (WER) is used for Automatic Speech Recognition (ASR) problems.
For Zindi competitions, we choose the evaluation metric for each competition based on what we want the model to achieve. Understanding each metric and the type of model you use each for is one of the first steps towards mastery of machine learning techniques.
Word Error Rate is used to compare the accuracy of the transcript or text produced by an ASR model.
WER is calculated as follows,
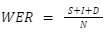
Where,
- S stands for substitutions,
- I stands for insertions,
- D stands for deletions,
- N is the number of words in the reference (that were actually said).
WER compares word for word so if a word is spelt incorrectly or if you do not use diacritics but the reference does you will recieve a bad WER score.
Evaluating Natural Language Processing models are tricky as no one metric takes into account all aspects of the model. For instance diacritics and spelling need to be correct to use WER, this becomes tricky when slang or a minority language is evaluated. When evaluating ASR models with WER punctuation is not included. This can be a problem as punctuation adds depth to text and meaning could be misconstrued.
According to Microsoft, a WER of 5-10% is considered to be good quality and is ready to use. A WER of 20% is acceptable, but you might want to consider additional training. A WER of 30% or more signals poor quality and requires customization and training.
This is a good goal to keep in mind but it is not the golden rule. Your WER depends on the size of your data and the language.
With this knowledge, you should be well equipped to use WER for your next machine learning project.
Why don’t you test out your new knowledge on one of our past automatic speech recognition competitions that uses WER as its evaluation metric? We suggest the AI4D Baamtu Datamation - Automatic Speech Recognition in WOLOF Challenge.