
AgriFieldNet India Challenge
'%3e%3ccircle r='20' fill='%23008'/%3e%3ccircle r='17.5' fill='%23fff'/%3e%3ccircle r='3.5' fill='%23008'/%3e%3cg id='d'%3e%3cg id='c'%3e%3cg id='b'%3e%3cg id='a' fill='%23008'%3e%3ccircle r='.875' transform='rotate(7.5 -8.75 133.5)'/%3e%3cpath d='M0 17.5.6 7 0 2l-.6 5L0 17.5z'/%3e%3c/g%3e%3cuse xlink:href='%23a' transform='rotate(15)'/%3e%3c/g%3e%3cuse xlink:href='%23b' transform='rotate(30)'/%3e%3c/g%3e%3cuse xlink:href='%23c' transform='rotate(60)'/%3e%3c/g%3e%3cuse xlink:href='%23d' transform='rotate(120)'/%3e%3cuse xlink:href='%23d' transform='rotate(-120)'/%3e%3c/g%3e%3c/svg%3e)
The dataset for this competition includes satellite imagery from Sentinel-2 cloud free composites (single snapshot) and labels for crop type that were collected by ground survey. The labels are derived from the survey conducted by IDinsight. The Sentinel-2 data are then matched with corresponding labels.
The dataset contains 7081 fields, which have been split into training and test sets (5551 fields in the train and 1530 fields in the test). For this challenge train and test sets have slightly different crop type distributions. The train set follows the distribution of ground reference data which is a skewed distribution with a few dominant crops being over represented. The test set was drawn randomly from an area weighted field list that ensured that fields with less common crop types were better represented in the test set. The goal was to generate a more uniform distribution of crop types for the test set. You will train your machine learning model on the fields included in the training set and will apply your model to the fields in the test set. You will submit your predictions for the crop type for each of the fields in the test dataset.
The data you will have access to (Satellite imagery and labels) are tiled into 256x256 chips adding up to 1217 tiles. The fields are distributed across all chips, some chips may only have train or test fields and some may have both. Since the labels are derived from data collected on the ground, not all the pixels are labeled in each chip. If the field ID for a pixel is set to 0 it means that pixel is not included in either of the train or test set (and correspondingly the crop label will be 0 as well).
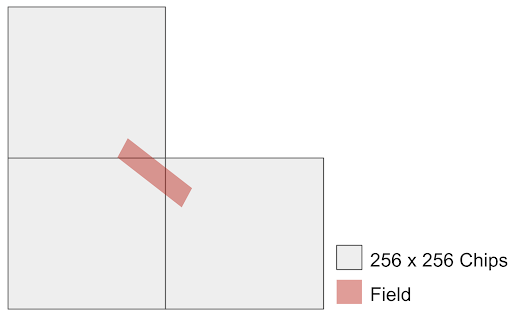
It’s important to know that some fields fall across multiple chips (in both train and test sets), and in this case there will be pixels associated with the same field ID in more than one chip. The following figure shows an example of a field that is spread across three chips. In this case, when you want to submit your prediction for the crop type of the corresponding field, you need to take into account all the pixels in these three chips as input.
Each chip has:
- Sentinel-2 imagery for 12 bands [B01, B02, B03, B04, B05, B06, B07, B08, B8A, B09, B11, B12] mapped to a common 10m spatial resolution grid.
- A raster layer indicating the crop ID for the fields in the train set.
- A raster layer indicating field IDs for the fields (both train and test sets).
Data for this competition is hosted on Radiant MLHub - open-access repository for geospatial data. You can access the data by creating a free account on Radiant MLHub.
You can download the data using Radiant MLHub Python Client (see the example notebook) or simply by going to the Radiant MLHub website.
The data is structured in three collections based on the metadata specification of SpatioTemporal Asset Catalog (STAC):
- Source collection: This contains all the source imagery for both train and test sets.
- Train label collection: This contains the field IDs and crop IDs for pixels that their field is in the train collection
- Test label collection: This contains only the field IDs for pixels that their field is in the test collection.
Variables definitions:
The label chips contain the mapping of pixels to crop type labels. The following pixel values correspond to the following crop types:
- 1 - Wheat
- 2 - Mustard
- 3 - Lentil
- 4 - No Crop/Fallow
- 5 - Green pea
- 6 - Sugarcane
- 8 - Garlic
- 9 - Maize
- 13 - Gram
- 14 - Coriander
- 15 - Potato
- 16 - Bersem
- 36 - Rice
Check out this starter notebook to see who you can download the dataset, build a simple model and prepare your first submission.
Files available for download:
The collections you download from Radiant MLHub will be structured as following:
Source imagery:
ref_agrifieldnet_competition_v1_source
|
|—ref_agrifieldnet_competition_v1_train_source_s2_{chip_id}
| |—B01.tif
| |—B02.tif
| |—B03.tif
| |—B04.tif
| |—B05.tif
| |—B06.tif
| |—B07.tif
| |—B08.tif
| |—B8A.tif
| |—B09.tif
| |—B11.tif
| |—B12.tif
| |—stac.json
Train labels:
ref_agrifieldnet_competition_v1_labels_train
|
|—ref_agrifieldnet_competition_v1_labels_train_{chip_id}
| |—field_ids.tif
| |—stac.json
| |—raster_labels.tif
Test labels:
ref_agrifieldnet_competition_v1_labels_test
|
|—ref_agrifieldnet_competition_v1_labels_test_{chip_id}
| |—field_ids.tif
| |—stac.json