
Côte d’Ivoire Byte-Sized Agriculture Challenge


Hi everyone,
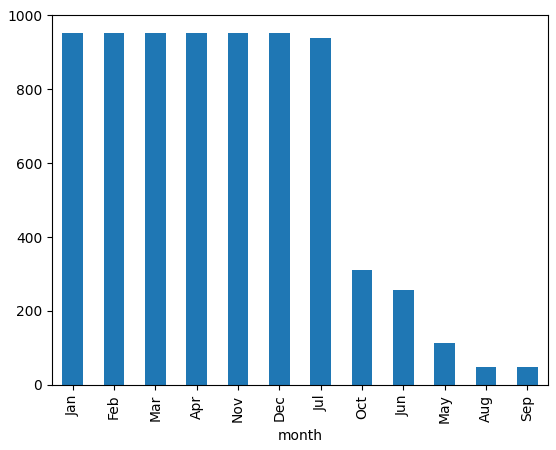
While working with the dataset, you may have noticed that some months are missing a significant number of images or even have no images at all. If we drop these months due to NaN values or missing entries, we end up with an imbalanced dataset, which could negatively affect model performance. On the other hand, keeping them introduces empty or incomplete data points.
As a result, the chart shows a heavy imbalance: some months have nearly complete data (~950 images), while others like May, August, and September have very few or none at all. If I hadn’t dropped the NaNs, I would have had a balanced timeline but with gaps that impact training and evaluation.
Discussion: How can we effectively handle missing image data in time-based datasets? Should we generate synthetic images or attempt to recollect data to balance things out?
If "serious" harvest does not occur in the missing months, you can just interpolate?
What if we calculate the average of June, July, October, and November NDVI values for August? Crops might follow similar seasonal trends yearly 🤔🤔🤔.
Maybe you could try the same months for previous years to fill the missing gaps? There is a risk that the crop changes from year to year, but with tree crops the risk is minimal. I wonder if you are missing images because these months were rainy and cloud cover obscured the image? If so it may be a similar problem each year.
Uhm 🤔 great point using the same months from previous years is a clever workaround especially for tree crops (cocoa, rubber, oil palm) since their spectral signatures stay relatively stable year-to-year.