
EY Biodiversity Challenge
Participants will be given locations (latitude and longitude) of frog presence across a portion of southeastern Australia over a period of 2 years from November 2017 to November 2019. This data will be used as the “target variable” in a machine learning model. Data from TerraClimate will be used as the “predictor variable” to train a machine learning model. In the end, this model will be used to predict the presence or non-presence of frogs in specific locations.
The dataset represents expert-validated occurrence records of calling frogs across Australia collected via the national citizen science project FrogID. FrogID relies on participants recording calling frogs using smartphone technology, after which point the frogs are identified by expert validators, resulting in a database of georeferenced frog species records.
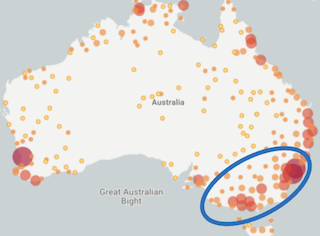
The total dataset includes 771,542 records of 218 species which is 86% of the known frog species in Australia. This data challenge will focus on a subset of the data from the southeastern portion of Australia. This sub-region has excellent diversity and large frog populations.
Note:
- Participants should NOT use latitude and longitude as “predictor” variables in their model. Using these data will create a spatially autocorrelated model that is not applicable to other regions and thus not generalized. The latitude and longitude locations should only be used to query the TerraClimate dataset to understand the environmental conditions surrounding the specific location.
- You may only use the TerraClimate dataset as a source for your “predictor” variables. It is suggested that participants utilize all the TerraClimate variables and consider alterations to the time window or statistical variations of the variables. Also, variable scaling and normalization should be considered.
- Students may use any common machine learning technique. This might include Random Forest, SVM, CNN, or regression variations.
The total dataset includes 771,542 records of 218 species which is 86% of the known frog species in Australia.