
Fault Impact Analysis: Towards Service-Oriented Network Operation & Maintenance by ITU

Well... it's finally over! This was an intense competition with strong competitors. I don't want to sound cliché, but I learned a tremendous amount. In fact, this was my first time tackling a time series problem, and I'm now completely captivated by it.
I'd like to invite everyone to share a concise summary of what worked for you and what didn't. The post-competition period is an excellent opportunity to learn from others' perspectives. So, let's share our insights, even if you weren't pleased with your final score!
What worked for me:
- Stratifield K fold with k = 10
- LGBM was my go-to model from day one
- The train data that I used was only when fault occur, so it was about ~90k rows

- Dropped from train data all de NE IDs with more than 5 NaNs
- I introduced seasonal features on data_rate using statsmodels
- Lag features! but 1 to 3. More than 3 the CV decrease.
- I dropped TA, access_success_rate, relation and fault duration.
- Feature engineering with cqi and mcs
- exponentially weighted on data_rate
df['data_rate_rolling'] = df['data_rate_lag'].ewm(span=4).mean()
- I applied an optimal threshold for all folds rather than a unique threshold for each fold

What didn't worked
- Approaches like regression, interpolation, and imputation for handling NaNs in the test set. Despite my efforts, none of these methods worked well
- Clustering
- Trend features
- Sin and Cos features
- I struggled to find alternatives to gradient boosting trees, primarily because handling NaNs in the test set was a significant challenge. This limited me to GBDT models. As a result, my ensembles lacked sufficient diversity, which I believe was a major setback.
- Feature engineering on NE ID: improve CV but decrease LB a lot.
(Bonus) What I couldn't make work:
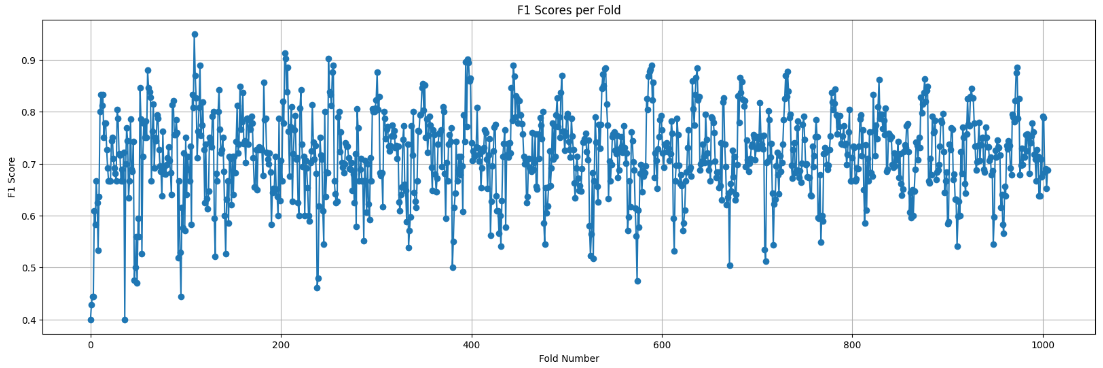
data_rate has a clear seasonal frequency of 12 hours. Precisely at hour 01, there is a shift in the number of faults x number of faults where data_rate decrease. Every hour 01 this shift happens and my models was unable to capture it. Below, you can see the F1 score per fold. The lowest score corresponds to hour = 01. Unfortunately, I couldn't find a solution to this issue.
90K rowsss??????
well.. the complete train data is about 900k rows 🤣
Damn or maybe thats what The top guys did tooo, I only used 7256 rows haha
Me too.
Thanks @yanteixeira - I had somewhat similar approach, but used all not just the observations with faults. This had a big impact on CV (and LB). I tested both quite a bit and always the one using all obs did much better. Then the sample jumps from 90k to 990k obs! I also used 3 lags - 3 seemed best. I just played a week, so not enough time for everything, but a few tests showed that an AE might also have worked well, but there was no time to tweak and nurture some DNN. So catboost it was all the way, no time even for other GBMs. In catboost I tried to adjust the class weights but it did not work, also I tried to calibrate the outputs a bit, not much gain, but I left it in all the way.
Albeit initially I would also use RF and AE + logarithmic regression on the non-NA obs, but it was too little time to pursue it, and catboost immeditately jumped to the top in anything I did, so I pretty quickly just switched to it and did not try to impute or balance anything. Later, when I had better features, I briefly tested the AE again, and it actually did really well ... so that would be on my todo list.
Towards the end I was getting quite creative with the features, e.g. using NE ID and combining both train and test samples, but this just worsened my score. My best private score was obtained early on, with a pretty simple model, and it got 0.737 on private. The latter attempts was just me scrambling to catch up with the top guys, I should have packed up and left real early. Then there was the disaster on closing day, when I could not get a score ... anyhow congrats and thanks for sharing.
@skaak
Thank you very much for sharing.
I joined the competition early so I could have ample time to experiment. In the first week, I used 800k rows (training data minus NaNs on NE IDs that had more than 5 NaNs). It gave me a score of 0.69 on the LB, which was a good score at the time (top 3).
However, when the current winner joined the competition, his first entry was so impressively high that I realized something was amiss with my approach. I completely deleted my entire code and started over with a fresh perspective. By reducing the rows to 90k and enhancing the features, I managed to achieve an LB score of 0.73. Unfortunately, after that, I hit a plateau and couldn't improve further.
I had an ensemble with LGBM and HistBoost that scored 0.74 on the private leaderboard. However, I made the mistake of making too many submissions (around 150), which led to mismanagement, and I ended up choosing suboptimal final submissions.
Well... lessons learned.
... and of course, as you so aptly display in that foto of yours, good strong coffee also helped a lot
Coffee was my gasoline in these past weeks
for me CV didn't help :)
You had to be, as always, careful. I had good local CV but terrible LB for one of my last models = clear sign of leakage, but only now realise what it was. I averaged across endTime and NE ID and used that as a feature, but of course there is a bit of leakage in there. I should only average inside the fold ... but at least, @Rakesh_Jarupula you had a nice improvement on private LB.