
Adbot Ad Engagement Forecasting Challenge
'%3e%3cpath fill='%23001489' d='M0 0v6h9V0z'/%3e%3cpath fill='%23e03c31' d='M0 0v3h9V0z'/%3e%3cg stroke='%23fff' stroke-width='2'%3e%3cpath id='d' d='m0 0 4.5 3L0 6m4.5-3H9'/%3e%3cuse xlink:href='%23b' stroke='%23ffb81c' clip-path='url(%23c)'/%3e%3c/g%3e%3cuse xlink:href='%23d' fill='none' stroke='%23007749' stroke-width='1.2'/%3e%3c/g%3e%3c/svg%3e)

By analyzing the submission file, we can observe that there are 96 IDs whose first forecast date is 2024-02-21. Since there are no IDs with a later date than this, we can infer that the host extracted the clients' historical data around February 21, 2024.
Now that we know that the present day is around 2024-02-21, we can assume that the other 89 IDs were inactive at the time of the extraction. This leaves us with two groups: (i) Active Clients and (ii) Inactive Clients.
Analyzing the Inactive Clients, I decided to break them into two subgroups: (i) those who went inactive in 2023 or earlier, and (ii) those who went inactive in 2024.
print(len(ids_with_2024_02_21)) -> 96
print(len(inactive_ids_with_2024)) -> 33
print(len(inactive_ids_with_2023)) -> 56
Another important point was brought up by by Kolesh on this post here . I wrote a code to find the IDs that have a gap greater than 8 days between their last historical record and the date requested in the submission file. There are 94 IDs with such a gap.
So far, we know that our data is not homogeneous at all. We have inactive clients, active clients, and clients from both groups that have data gaps leading up to the submission file.
It would be impossible to know what to do if we didn't have the exact same situation in the data given to us. In the provided data, we have several IDs that went inactive for a period of time but suddenly came back and started publishing ads again. We can learn from these IDs to come up with a solution for the forecast period.
I will show one of these types of clients:
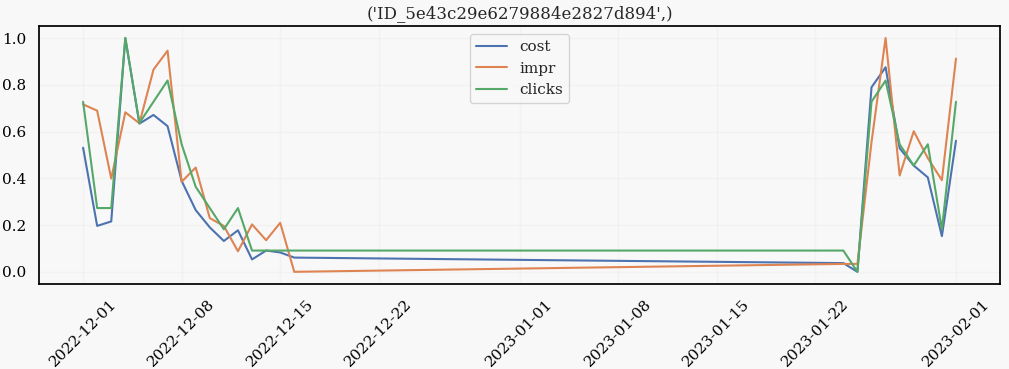
We can see that the days leading to inactivity are marked by a constant decrease in the metric features. Also, when the client decides to return to the platform, there is no "adaptation" period. The metrics, instead, behave as if the inactivity never happened.
While analyzing these "gap" clients, I decided on my strategy:
- For inactive clients, the forecast will show a decreasing rate in the metrics.
- Clients with a gap between the historical data and the submission date will have their dates updated to be closer to the submission date.
Forecasting
For the active clients, I realized it was important to maintain their historical patterns because, well, they are still active. So I wrote a code to analyze every feature for every ID in this group and classify whether a given feature for a given ID is stationary or not. If yes, then I forecast all the features using SARIMA; otherwise, a moving average was used (the same one I posted here on the forum).
For the inactive clients, the descriptive ad features are forecasted using a moving average, and the metric features use a decreasing rate. We apply different decreasing rates for Inactives_2023 and Inactives_2024 because the inactive group of 2024 shows higher metrics at the beginning of the year, so consequently, they will also take a longer time to decrease.
After the script is run, I concatenate all the groups to form my final dataframe. The final data transformation updates the last recorded dates for the "gap IDs" clients.
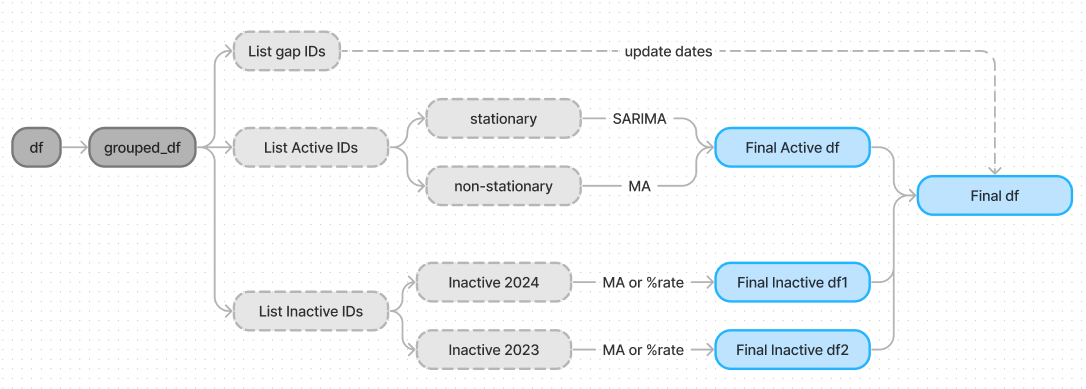
Finally, a CatBoost regressor is trained on the entire dataset and then used to make the predictions.
This is brilliant!
Good Job ! Amazing workflow
Have you been disqualified?
@ihar Yes, I received an email today stating that I have been disqualified
did they mention the reason?!
They didn't like that I used 'id' as one of the model features.
It's against the rules of Zindi
@Ebiendele Can you show me where this rule is? I'm unable to find it.
using the ID in this competition is not considered cheating, infact it's really important to include it in the training set as it helps the model differentiate between historical patterns of each client.
It was discussed some years back I can't remember the challenge the use of id as a feature in model is not useful to the clients
It might definitely serve as a good feature in modelling but we're not meant to use it that what bring disqualification
@Ebiendele A discussion from years back can't be considered an official rule. This rule should be written in the competition description.
Also, the submission file only includes clients from the training data, so basically the competition is asking for the model to generalize for those clients. If the host wants the models to generalize for any clients, the submission should include different clients from the training data, or you should state in the description that using IDs is against the rules.
What is very unfair is telling me about this 'rule' after the competition has ended. It's very disrespectful to the person who invested a lot of time in the competition.
@Amy_Bray @Nelly43 can one of you answer here?
what was the score without the 'id' column? btw this was impressive. you really did extensive analysis
Hello @yanteixeira,
We recognise that you, and everyone else on the leaderboard, have put considerable effort into this competition, and our team understands your situation.
Please note that the ID is not a feature from the data but rather it was created through a random process that is virtually different from and unrelated to the customer-client interaction on the Adbot platform. Moreover, an important quality of a good machine learning model is generalising over new/unseen data, which includes the test set as well as any new set of data that is created after the model has been trained and validated.
For this competition, it was highlighted that winning solutions would have to:
This was to primarily demonstrate the interpretability and usability of your model(s).
Using the ID as a feature in your model not only introduces a leakage (an issue that was raised in an earlier discussion), it also renders the model impractical since there is no real-world interpretation of the relationship between the IDs and number of clicks, or any other variable for that matter.
Zindi competitions are often based on real-world problems with winning solutions ultimately being handed to hosts for implementation. Therefore, to help ensure your solution wins, it would be useful to build robust models that not only adhere to competition rules but also incorporate best practices. This is because your work will always be evaluated in the same way as when delivering solutions to a client, especially when emphasised in the competition's details.
I hope this helps.
Best,
Nelson.
@Nelly43 Thanks for the answer. By the way, if this text had been the email I received, I would have understood right away.
In any case, we learn from our mistakes. See you all in the next one