
Inundata: Mapping Floods in South Africa
'%3e%3cpath fill='%23001489' d='M0 0v6h9V0z'/%3e%3cpath fill='%23e03c31' d='M0 0v3h9V0z'/%3e%3cg stroke='%23fff' stroke-width='2'%3e%3cpath id='d' d='m0 0 4.5 3L0 6m4.5-3H9'/%3e%3cuse xlink:href='%23b' stroke='%23ffb81c' clip-path='url(%23c)'/%3e%3c/g%3e%3cuse xlink:href='%23d' fill='none' stroke='%23007749' stroke-width='1.2'/%3e%3c/g%3e%3c/svg%3e)

Huge thanks to my teammates @nymfree and @DJOE . We could have not done this without the team work.
Our solution consists of four key stages:
1. Exploratory Data Analysis (EDA) & Data Preparation
We perform EDA on composite images to determine the optimal band combination for flood probability prediction. The best-performing band for this task was Moisture Stress.
2. Image Classification
Using Moisture Stress images, we train an image classifier (eva02_tiny_patch14_224) to predict the probability of flooding at each location. This feature significantly improves the overall model performance as a predictive feature on its own and later for the normalization stage
3. Modelling
We trained nine different models using a combination of flood probability, lagged precipitation values, rolling statistics, exponentially weighted moving averages (EWMA), and event time indicators. We used a 10 fold CV based on StratifiedGroupKFold for all the models and the cv scores for each are shown below
- XGBoost - 0.002344928
- LightGBM - 0.002392372
- FastAI Tabular - 0.002656410
- FastAI GatedConv - 0.002614245
- FastAI 1DConv - 0.002568254
- FastAI TabTransformer - 0.002845684
- TabNet - 0.002566037
- Wavenet-GRU - 0.002619232
- ResNet1D - 0.002407528
4. Ensembling
We ensemble model predictions using Nelder-Mead optimization and apply flood probability normalization to improve generalization and predictive performance. The normalization DOES NOT USE THE LEAKED ROW ORDER as shown by @snow but instead we use the flood probability from stage 2 from the image classifier to perform normalization and this is a generalizable approach since the flood probability is a predictive feature.
- Mean Average Ensemble - 0.002088235
- Optimized Ensemble - 0.002072086
The above cv scores are without the normalization step btw! So you can see how ensembling a diverse range of models can lead to a really huge CV improvement !
Now the oof score after normalizing: - 0.00201654
Leaderboard Scores
- Optimized public LB / private LB (without normalizing): 0.002125168 / 0.002322155
- Optimized public LB / private LB (with normalizing): 0.002105851 / 0.002280238
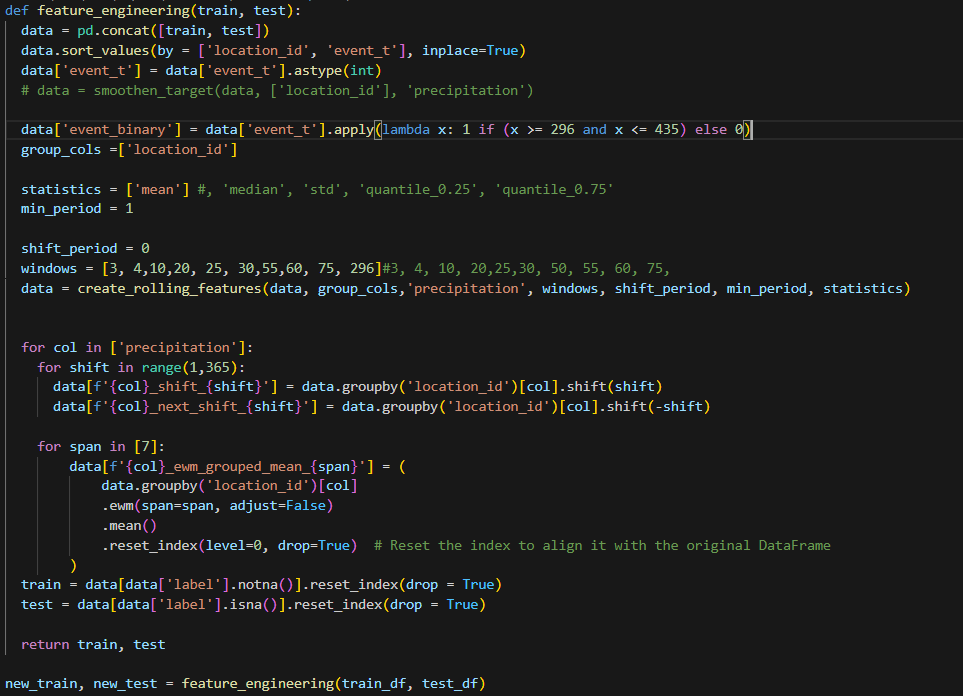
GBDT Modelling
Basically all the features I used on all the gbdt models(xgboost and lightgbm) are shown below plus now add the flood probability from stage 2 and the precipitation from the original data. I then tuned the features of each using optuna.
Conclusion
Our success in this challenge came from a combination of:
- Diverse modeling approaches (GBDT + deep learning)
- Extensive feature engineering
- Careful cross-validation strategy
- Ensembling and flood probability normalization
While GBDT models provided robust predictions, deep learning models captured additional complexity, and ensembling them together led to a significant improvement.
This post covers my contributions using GBDT. My teammates will share their insights into deep learning approaches and other aspects of our pipeline. Feel free to ask any questions!
Github link:
Kindly star the REPO if you find it insightful as it encourages us to open source more of our work! And I hope it encourages more Winners (who we have seen in some recently concluded competions) who are not willing to share their winning solutions with the community to share as we are all here to learn.
Wow, this is impressive congratulations to your team🎉
Thank you!
Congratulations guys, nicely done
Thank you!
Congratulations. Thank you for sharing your solutions, this will help others to learn
You're welcome
Congratulations! I'm looking forward to use the image features that you extracted to measure the impact on my model
Nice! We have provided the notebooks to do that. Specifically the first stage and second stage notebooks
Convnets / tabtransformer modelling
Using @koleshjr's great feature engineering work, I developed 3 models based on convnets and transformers. Small and shallow networks worked best here. Additionally, it was important to leverage fastai's tried and tested training pipeline (data pre-processing and normalization methods being very important here).
1d CNN model
Gated conv model
Transformer model
Notice that the forward method takes 2 parameters
The "_" is used by fastai for bookkeeping purposes.
These 3 models are very diverse and are therefore good candidates foe ensembling.
Impressive work, congrats 🎊
thanks for sharing your solution, this is really informative .
You're welcome
congratulations !
Thanks